Http协议分析与攻击
HTTP协议分析
概述
HTTP是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。 客户端和服务端通过交换各自的消息进行交互。由像浏览器这样的客户端发出的消息叫做 requests(请求),被服务端响应的消息叫做 responses(响应)。
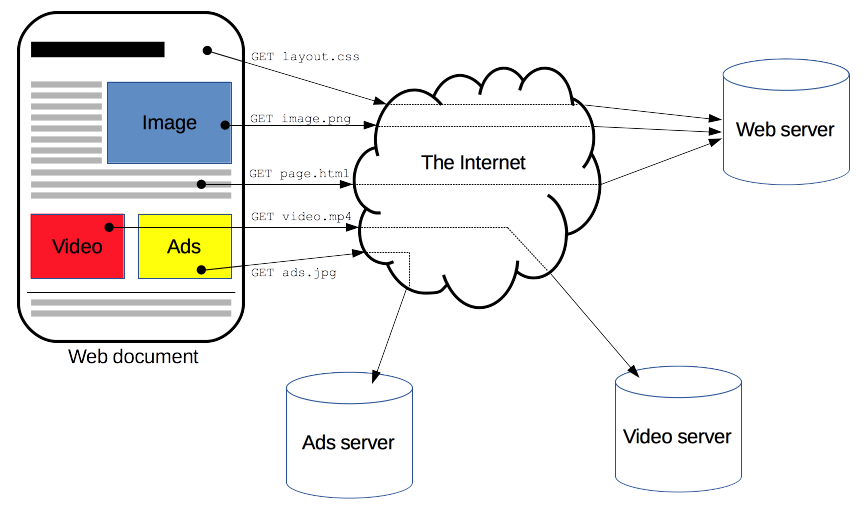
一个完整的Web文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。如下图所示:
HTTP 的基本性质
HTTP 是简单的 虽然下一代HTTP/2协议将HTTP消息封装到了帧(frames)中,HTTP大体上还是被设计得简单易读。HTTP报文能够被人读懂,还允许简单测试,降低了门槛,对新人很友好。
HTTP 是可扩展的 在 HTTP/1.0 中出现的 HTTP headers 让协议扩展变得非常容易。只要服务端和客户端就新 headers 达成语义一致,新功能就可以被轻松加入进来。
HTTP 是无状态,有会话的 HTTP是无状态的:在同一个连接中,两个执行成功的请求之间是没有关系的。这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。而使用HTTP的头部扩展,HTTP Cookies就可以解决这个问题。把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
注意,HTTP本质是无状态的,使用Cookies可以创建有状态的会话。
HTTP 流
当客户端想要和服务端进行信息交互时(服务端是指最终服务器,或者是一个中间代理),过程表现为下面几步:
- 打开一个TCP连接:TCP连接被用来发送一条或多条请求,以及接受响应消息。客户端可能打开一条新的连接,或重用一个已经存在的连接,或者也可能开几个新的TCP连接连向服务端。
发送一个HTTP报文:HTTP报文(在HTTP/2之前)是语义可读的。在HTTP/2中,这些简单的消息被封装在了帧中,这使得报文不能被直接读取,但是原理仍是相同的。
1 2 3
GET / HTTP/1.1 Host: developer.mozilla.org Accept-Language: fr
读取服务端返回的报文信息:
1 2 3 4 5 6 7 8 9 10
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
- 关闭连接或者为后续请求重用连接。
HTTP 报文
HTTP/1.1以及更早的HTTP协议报文都是语义可读的。在HTTP/2中,这些报文被嵌入到了一个新的二进制结构,帧。帧允许实现很多优化,比如报文头部的压缩和复用。即使只有原始HTTP报文的一部分以HTTP/2发送出来,每条报文的语义依旧不变,客户端会重组原始HTTP/1.1请求。因此用HTTP/1.1格式来理解HTTP/2报文仍旧有效。有两种HTTP报文的类型,请求与响应,每种都有其特定的格式。
请求
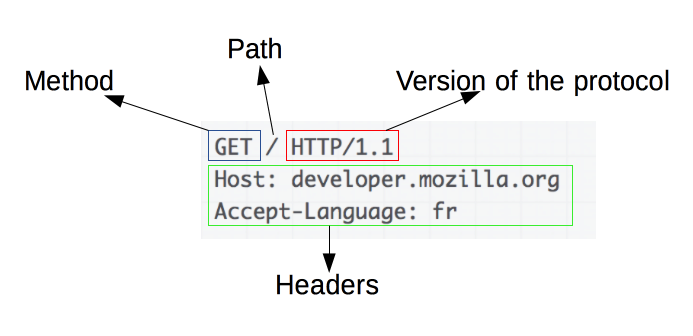
请求由以下元素组成:
Method: 经常是由一个动词像GET, POST 或者一个名词像OPTIONS,HEAD来定义客户端的动作行为。通常客户端的操作都是获取资源(GET方法)或者发送HTML form表单值(POST方法)Path: 要获取的资源的路径,通常是上下文中就很明显的元素资源的URL,它没有protocol (http://),domain(developer.mozilla.org),或是TCP的port(HTTP一般在80端口)。Version: 通常为HTTP/1.1Headers: 为服务端表达其他信息的可选头部headers。Body: 对于一些像POST这样的方法,报文的body就包含了发送的资源,这与响应报文的body类似。
响应
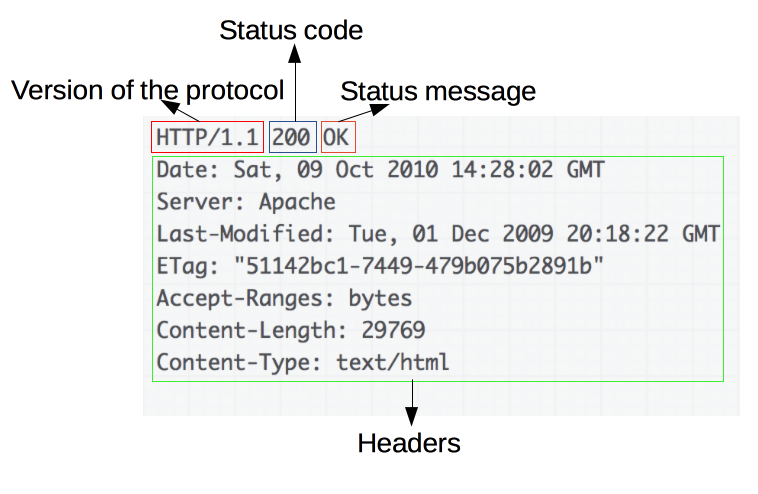
响应报文包含了下面的元素:
Version: HTTP协议版本号。Status code: 一个状态码(status code),来告知对应请求执行成功或失败,以及失败的原因。Status message: 一个状态信息,这个信息是非权威的状态码描述信息,可以由服务端自行设定。Headers: HTTP headers,与请求头部类似。Body: 可选项,比起请求报文,响应报文中更常见地包含获取的资源body。
我们可以使用 Wireshark 进行协议分析(访问stu-xdwlan登陆页面),通过 wireshark 抓包结果如下
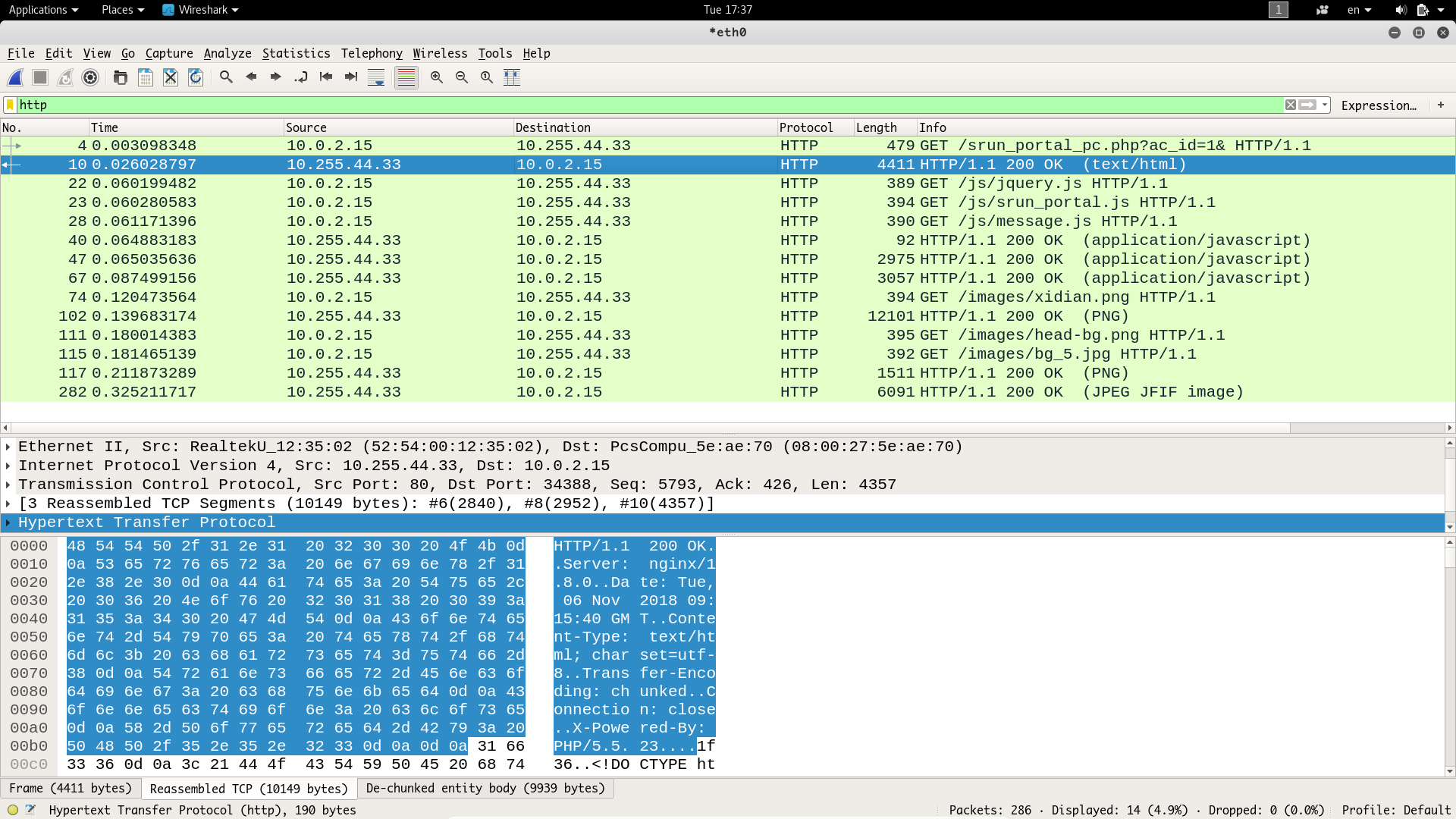
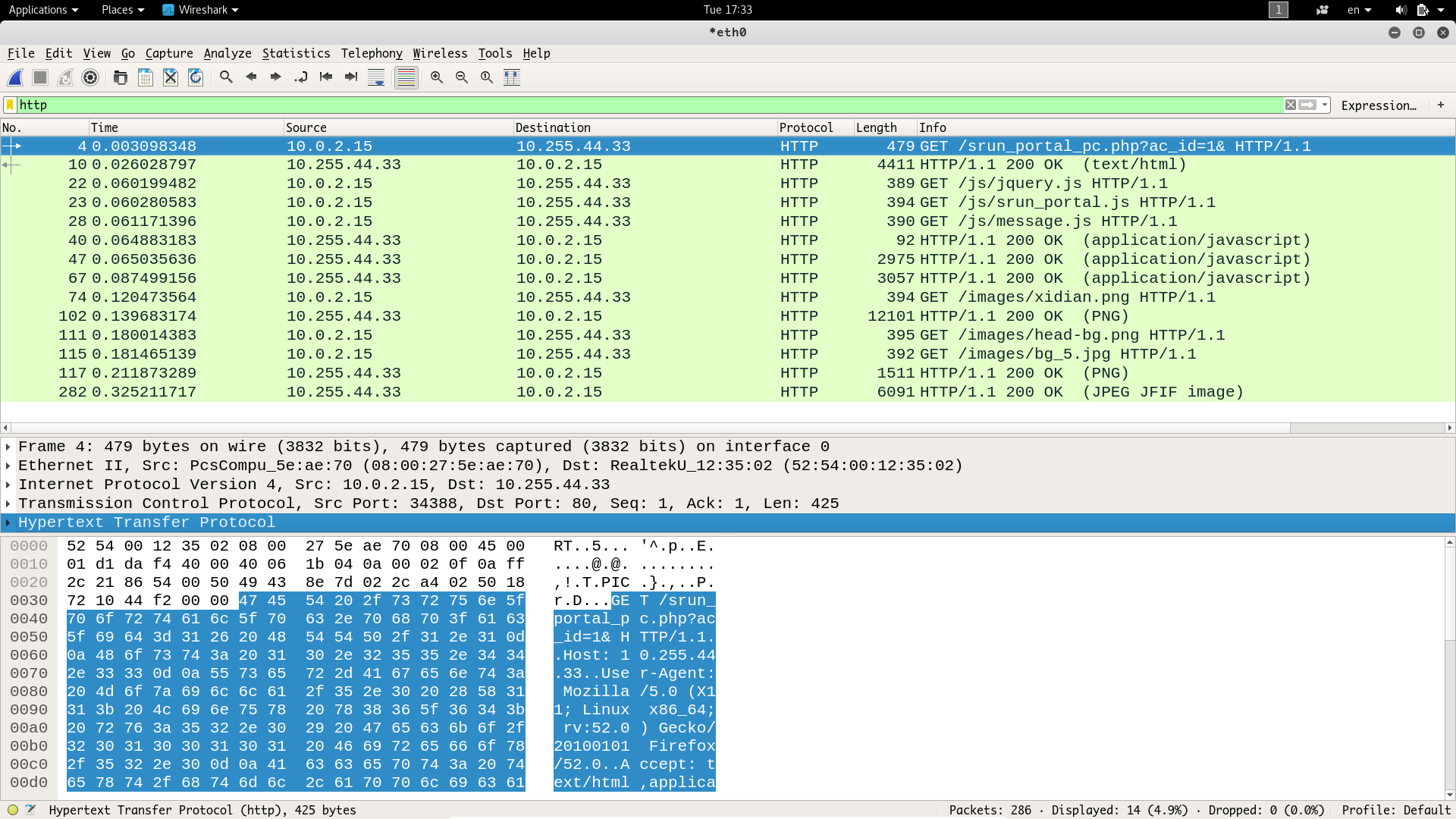
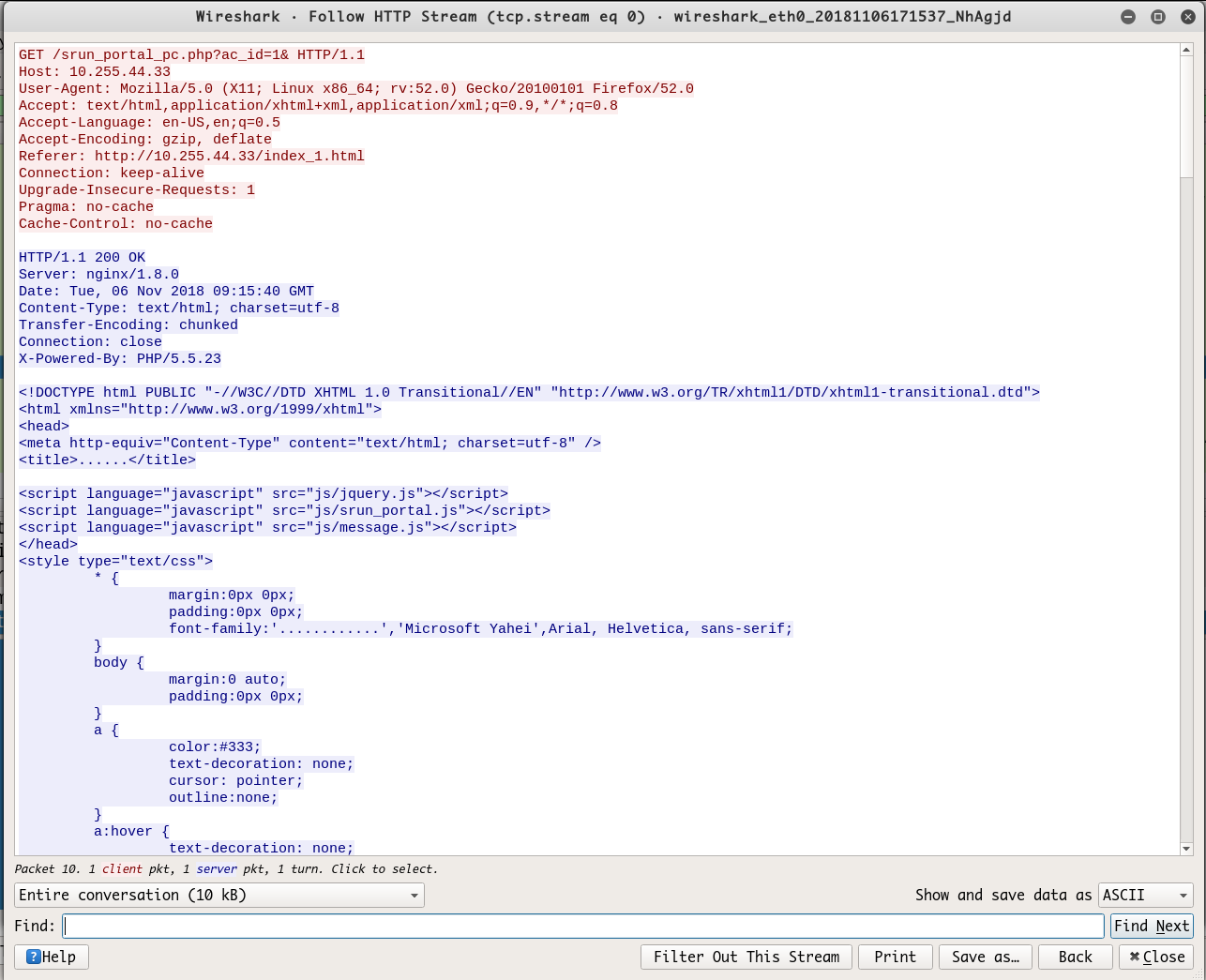
使用 Python 抓取 http 页面
Python中有很多用于实现http请求的库,如urllib, urllib2(二者均为官方提供的库), urllib3, requests等等,但网上强烈推荐使用requests,因为它的API 设计得非常优雅。因此,我也果断选择了requests。
Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。 ——来自官网
Requests基本用法
1
2
3
4
5
6
7
8
9
10
11
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass’))
>>> r.status_code
200
>>> r.headers['content-type’]
'application/json; charset=utf8’
>>> r.encoding
'utf-8’
>>> r.text
u'{"type":"User"...’
>>> r.json()
{u'private_gists': 419, u'total_private_repos': 77, ...}
使用会话
会话对象让你能够跨请求保持某些参数。它也会在同一个 Session 实例发出的所有请求之间保持 cookie, 期间使用 urllib3 的 connection pooling 功能。所以如果你向同一主机发送多个请求,底层的 TCP 连接将会被重用,从而带来显著的性能提升。会话对象具有主要的 Requests API 的所有方法。
我们可以跨请求保持一些 cookie:
1
2
3
4
5
6
7
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
# '{"cookies": {"sessioncookie": "123456789"}}'
会话也可用来为请求方法提供缺省数据。这是通过为会话对象的属性提供数据来实现的:
1
2
3
4
5
6
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
会话还可以用作前后文管理器:
1
2
with requests.Session() as s:
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
这样就能确保 with 区块退出后会话能被关闭,即使发生了异常也一样。因此我选择了使用这种方式。
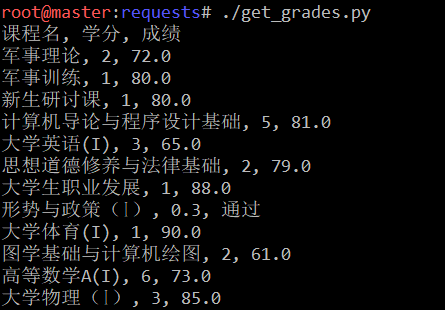
实例-从旧版教务系统获取成绩
下面将展示各个关键函数,并做简要说明
主函数
1
2
3
4
5
6
if __name__ == "__main__":
with requests.Session() as s:
s.headers = headers
log_in(s)
thead, tbody = get_grades(s)
print_grades(thead, tbody)
主函数非常简单,先登陆,登陆成功后获取成绩,然后输出成绩
全局变量
1
2
3
4
5
6
7
8
9
10
11
12
13
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Upgrade-Insecure-Requests': '1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
url_login = 'http://ids.xidian.edu.cn/authserver/login?service=http%3A%2F%2Fjwxt.xidian.edu.cn%2Fcaslogin.jsp'
url_grade = 'http://jwxt.xidian.edu.cn/gradeLnAllAction.do?type=ln&oper=qbinfo&lnxndm=2017-2018%D1%A7%C4%EA%B5%DA%B6%FE%D1%A7%C6%DA(%C1%BD%D1%A7%C6%DA)'
子函数1——log_in
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def log_in(s):
"""登陆旧版教务系统
:s: session
:returns: TODO
"""
resp = s.get(url_login, timeout=5) #获取登录页面
err_status_handler(resp) # 获取失败则报错
page = resp.text # 获取 HTML 文本
root = html.fromstring(page) # 获取 DOM 根结点
postdata = {'submit': ''} # 初始化等会要 POST(教务系统登录页面提交表单时使用的 POST 方法) 的数据
postdata['username'] = '123456789'
postdata['password'] = 'password'
other_inputs = root.xpath('//*[@id="casLoginForm"]/input') # 要登录成功还需要其它信息(它们隐含在登录页面中)
for input_element in other_inputs:
postdata[input_element.name] = input_element.value
r = s.post(url_login, data=postdata, timeout=5) # 提交登录表单
err_status_handler(r)
对于这个函数的讲解,请看代码中的注释
子函数2——get_grades
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
def get_grades(s):
"""获得成绩
:thead: TODO
:tbody: TODO
:returns: TODO
"""
resp = s.get(url_grade, timeout=5) # 登录完成后就可以获取到成绩页面
err_status_handler(resp)
page = resp.text
root = html.fromstring(page)
thead = root.xpath('//*[@id="user"]/thead/tr') # 获得成绩表格的表头(属性)
#print thead
assert thead != None
tbody = root.xpath('//*[@id="user"]/tr') # 获得成绩表格的表体(元组)
#print tbody
assert tbody != None
# iterate thead[0]'s all children
thead2 = [th.text.strip() for th in thead[0]] # 将所有属性放到列表(list,也就是数组)中
# tbody = [[td.text.strip() for td in tr] for tr in tbody]
tbody2 = [] # 准备放各科成绩
for tr in tbody:
i = 0
# 对 tr(每科成绩)做一些必要的修改(提取字符串)
temp_tr = []
for td in tr:
if i == 6:
temp_tr.append(td.find('p').text.strip())
else:
temp_tr.append(td.text.strip())
i += 1
# 然后放到 tbody2 中
tbody2.append(temp_tr)
return thead2, tbody2
见注释
子函数3——print_grades
1
2
3
4
5
6
7
8
9
10
11
12
13
14
def print_grades(thead, tbody):
"""输出成绩
:thead: TODO
:tbody: TODO
:returns: TODO
"""
i = 0
for tr in tbody:
if i == 0:
print "%s, %s, %s" % (thead[2], thead[4], thead[6])
print "%s, %s, %s" % (tr[2], tr[4], tr[6])
i += 1
运行结果