16位汇编程序设计
为什么要学习汇编语言?
- 嵌入式系统:在特定硬件下,对程序的大小和运行速度需要高度优化的情况。
- 驱动程序的设计者;操作系统内核的设计者;编译程序的设计者。
- 有助于对计算机硬件、操作系统、应用程序之间交互的整体理解。
- 突破高级语言的局限:高级语言中嵌入汇编。
汇编语言通常在编程语言中排名第10左右
Intel处理器体系结构的发展
处理器微体系结构决定了处理器的性能、成本等指标,故其体系结构在不断地发展变化。
| 年份 | 微处理器型号 | 体系结构 |
|---|---|---|
| 1978 | 8086 | Intel IA-32架构先导,第1个16位处理器 |
| 1985 | 80386 | Intel IA-32架构,第1个32位处理器 |
| 1995-1999 | P6家族 | Intel IA-32架构(超标量微体系结构) |
| 2000-2006 | Pentium 4 | Intel IA-32架构(NetBurst微体系结构) |
| Pentium 4(6xx、5xx) | Intel 64架构 | |
| 2003 | Pentium M | 增强的Intel IA-32移动架构 |
| 2005-2007 | Pentium Extreme | Intel 64架构(NetBurst微体系结构) |
| 2006-2007 | Core Duo | 增强的Pentium M微体系结构 |
| 2006 | Pentium双核,Core 2 Duo | Intel 64架构(Core微体系结构,65nm) |
| 2007 | Core 2 Duo E8000,Quad Q9000 | Intel 64架构(增强Core微体系结构,45nm) |
| 2008 | Atom | Intel 64架构(Atom微体系结构,45nm) |
| 2008 | Core i7 900 | Intel 64架构(Nehalem微体系结构,45nm) |
| 2010 | Core i7、i5、i3 | Intel 64架构(Westmere微体系结构,32nm) |
| 2011 | 第二代Core i7、i5、i3 | Intel 64架构(Sandy Bridge微体系结构,32nm) |
| 2012 | 第三代Core i7、i5、i3 | Intel 64架构(Ivy Bridge微体系结构,22nm) |
| 2013 | 第四代Core i7、i5、i3 | Intel 64架构(Haswell微体系结构,22nm) |
| 2015 | 第五代Core i7、i5、i3 | Intel 64架构(Broadwell微体系结构,14nm) |
其变化内容大致如下:
- 主存分段
- 寄存器结构
- 主存寻址空间
- 外部总线宽度
- 更宽的内部数据通路
- 保护模式
- 分段存储模型
- 平坦存储模型
- 分页虚存管理
- 流水线技术
- 超标量
- 分支预测
- 动态执行/推测执行/乱序
- 高速缓存技术;Smart Cache
- 扩展指令集
- 超线程技术;多核技术
- 硬件虚拟化技术
- 集成的多通道存储控制器
- QPI
- 集成的图形处理单元
- Turbo Boost
- 环形内部总线(第二代Core i7、i5、i3)
- 16位→32位→64位
- 制造工艺:65nm→45nm→32nm→22nm→14nm
单核处理器 8086
为什么选择 8086
- 单核处理器是多核处理器的基础。
- 从8086 CPU开始,Intel CPU设计采用了向后兼容(backward compatibility,也称作向下兼容Downward Compatibility)的特性。
- 单核的8086 CPU成为其后Intel CPU的基石。
8086 简介
- 8086 CPU有三个版本:8086、8086-2、8086-1,仅时钟频率不同,依次为5Mhz、8Mhz、10Mhz。
- 8086 CPU具有如下功能特性:
- 直接主存寻址能力1MB;
- 体系结构是针对强大的汇编语言和有效的高级语言设计的;
- 14个16位寄存器;
- 24种操作数寻址方式;
- 操作数类型:位、字节、字和块;
- 8、16位无符号和带符号二进制或十进制运算,包括乘法和除法。
- 特点:
- 实地址模式
- 小端存储(反常识),如 5678H 表式为 7856H
体系结构
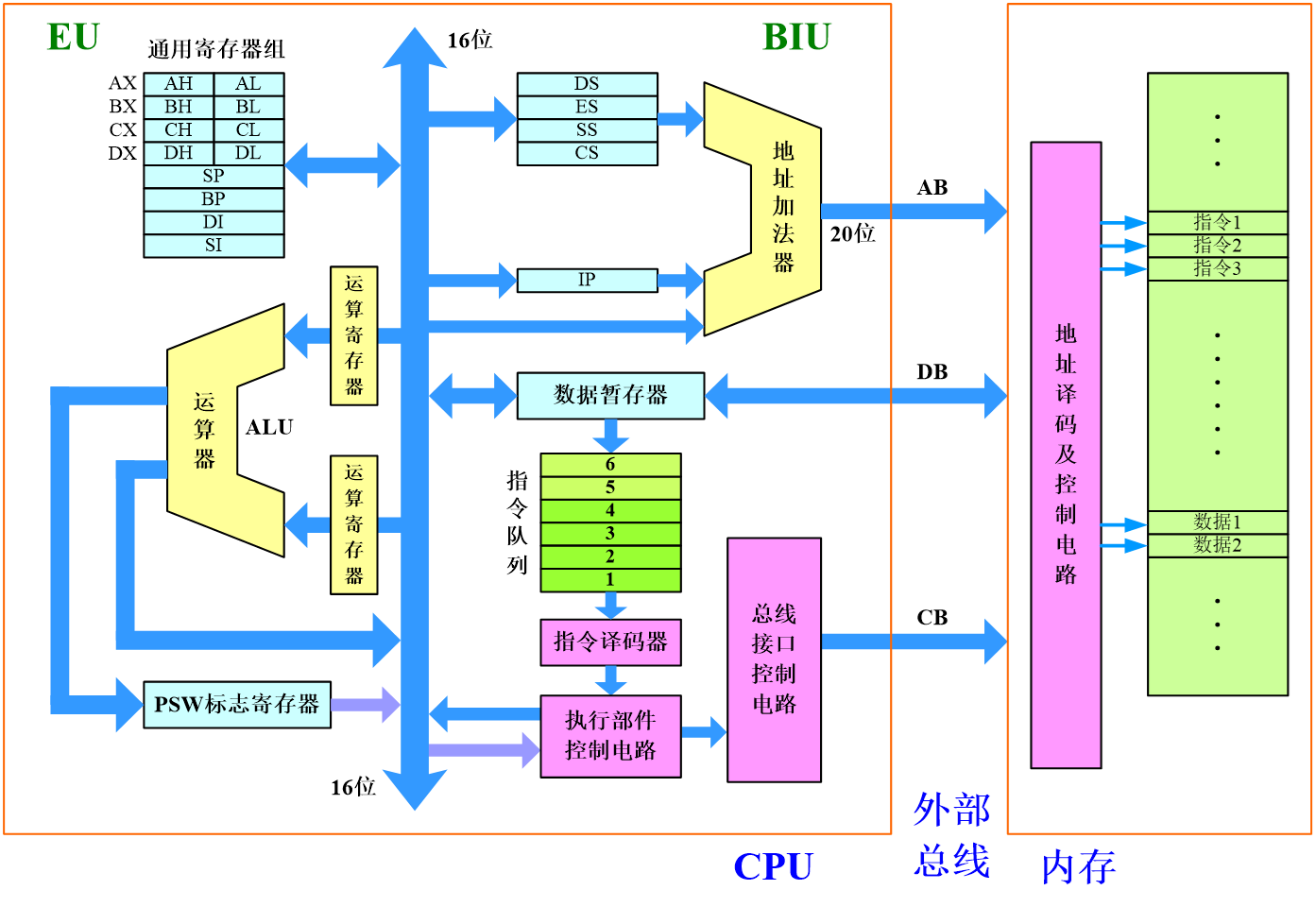
- 总线接口单元BIU(Bus Interface Unit): 负责与存储器、I/O接口传递数据,具体完成:
- 从内存取指令,送到指令队列
- 配合EU从指定的内存单元或IO端口取数据
- 将EU的操作结果送到指定的内存单元或IO端口
- 执行单元EU(Execute Unit):负责指令的执行(算术、逻辑、移位运算,有效地址计算,控制命令、……)
由于有指令队列,BIU和EU可并行工作
寄存器结构
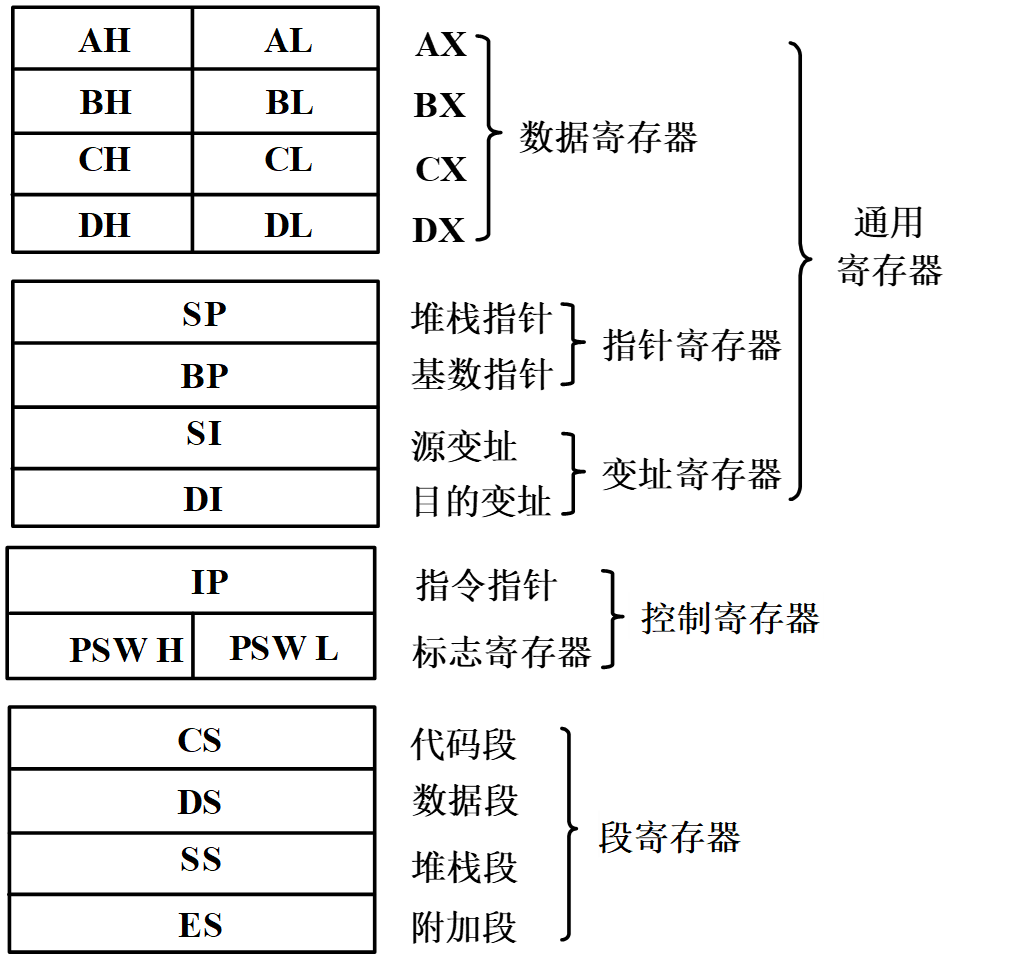 其中各寄存器说明如下:
其中各寄存器说明如下: 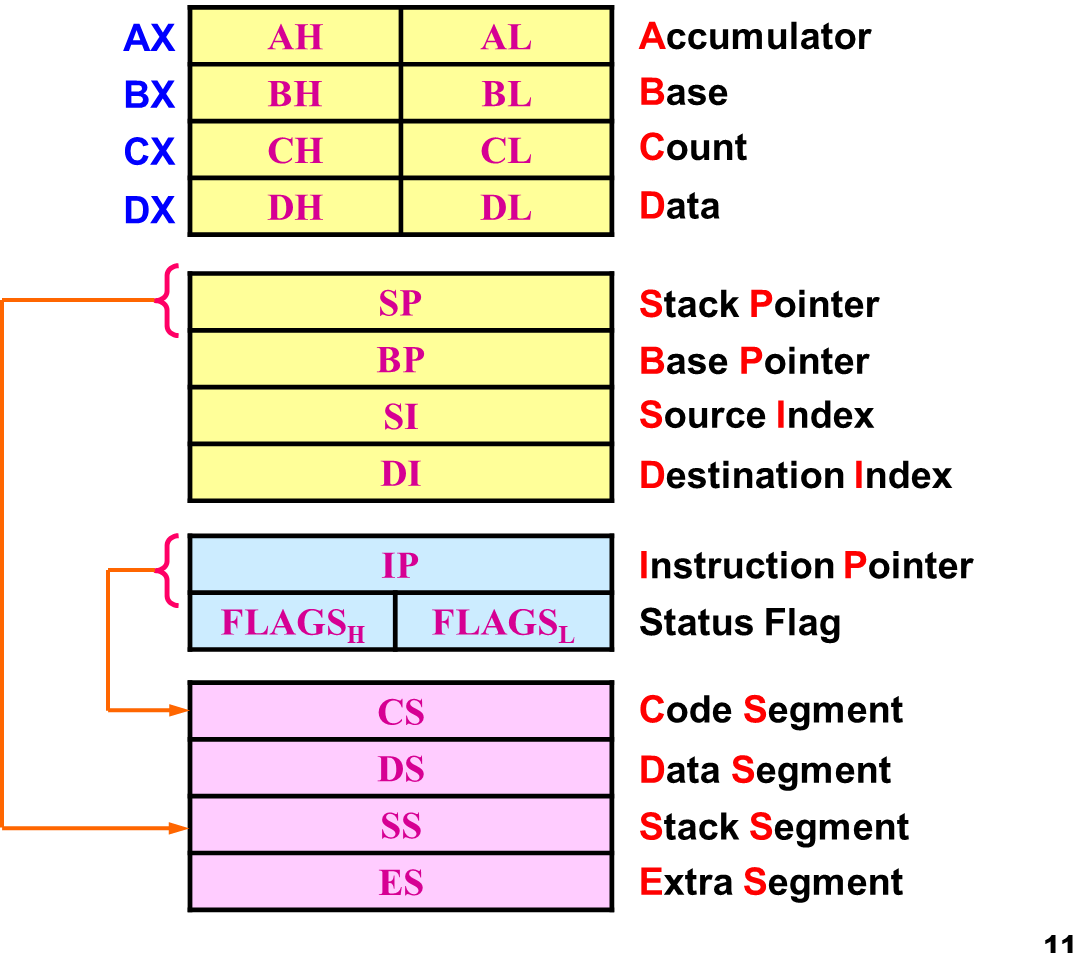
关于寄存器的更多信息可以参考这篇文章 x86 Assembly Registers[All Types Explained]
对于有保护模式的32位的 CPU (如80386),其寄存器有如下特点:
- 每个寄存器可作32位或16位使用。
- 一些16位的寄存器也可以作为两个单独的8位使用。
其余通用寄存器的低16位有独立的名字,但不能进一步细分。下面列出的16位寄存器通常只在编写运行于实地址模式(8086只有实地址模式,保护模式首次出现在80386中)下的程序时才使用。
32位 16位 高8位 低8位 EAX AX AH AL EBX BX BH BL ECX CX CH CL EDX DX DH DL 32位 16位 ESI SI EDI DI EBP BP ESP SP
主存结构
双体
既可以实现16位存储,也可以实现8位存储。 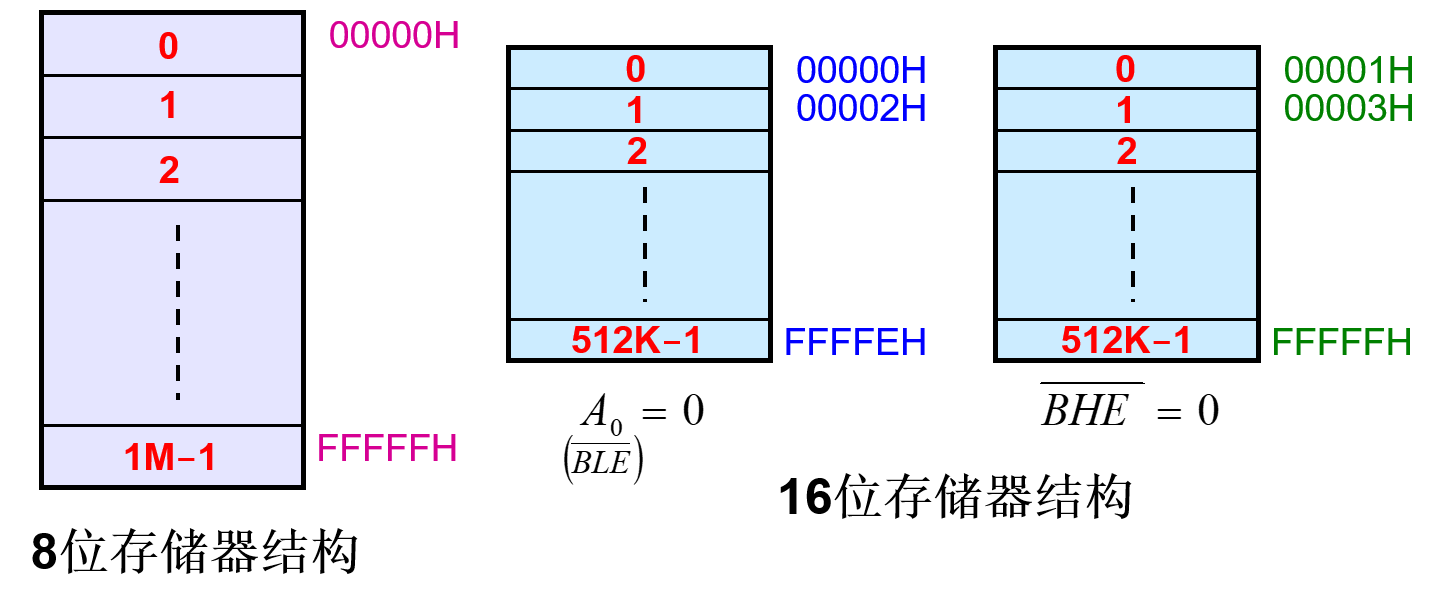
分段
1
物理地址 = 段地址*16+段内偏移地址
例如:形式地址6832H:1280H → 物理地址?(68320H + 1280H = 695A0H)
优点:
- 代码、数据量不大 → 使其处于同一段内(64KB范围内)→ 可减少指令长度、提高运行速度。
- 内存分段为程序的浮动分配创造了条件。
- 各个分段之间可以重叠。
8086 CPU 执行程序时,当前指令的存储地址为(CS)×16+(IP)。当CS不变、IP单独改变时,会发生段内的程序转移;当CS改变时,会发生段间的程序转移。
段寄存器的使用约定如下: 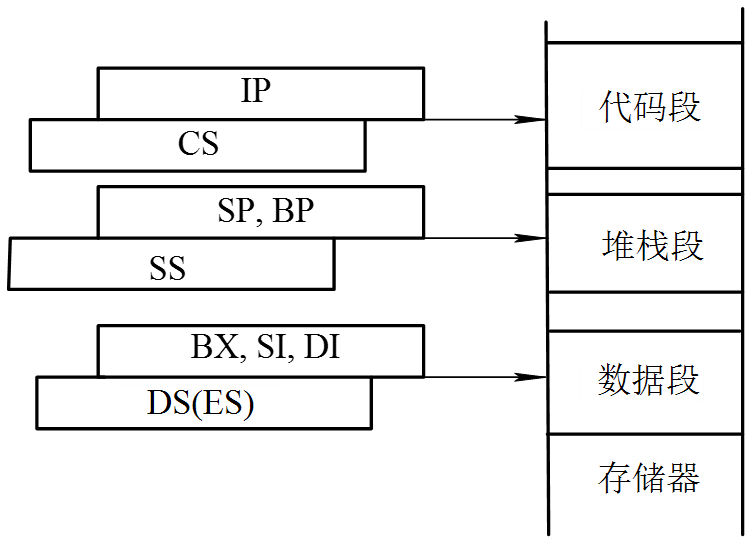
主存结构如下: 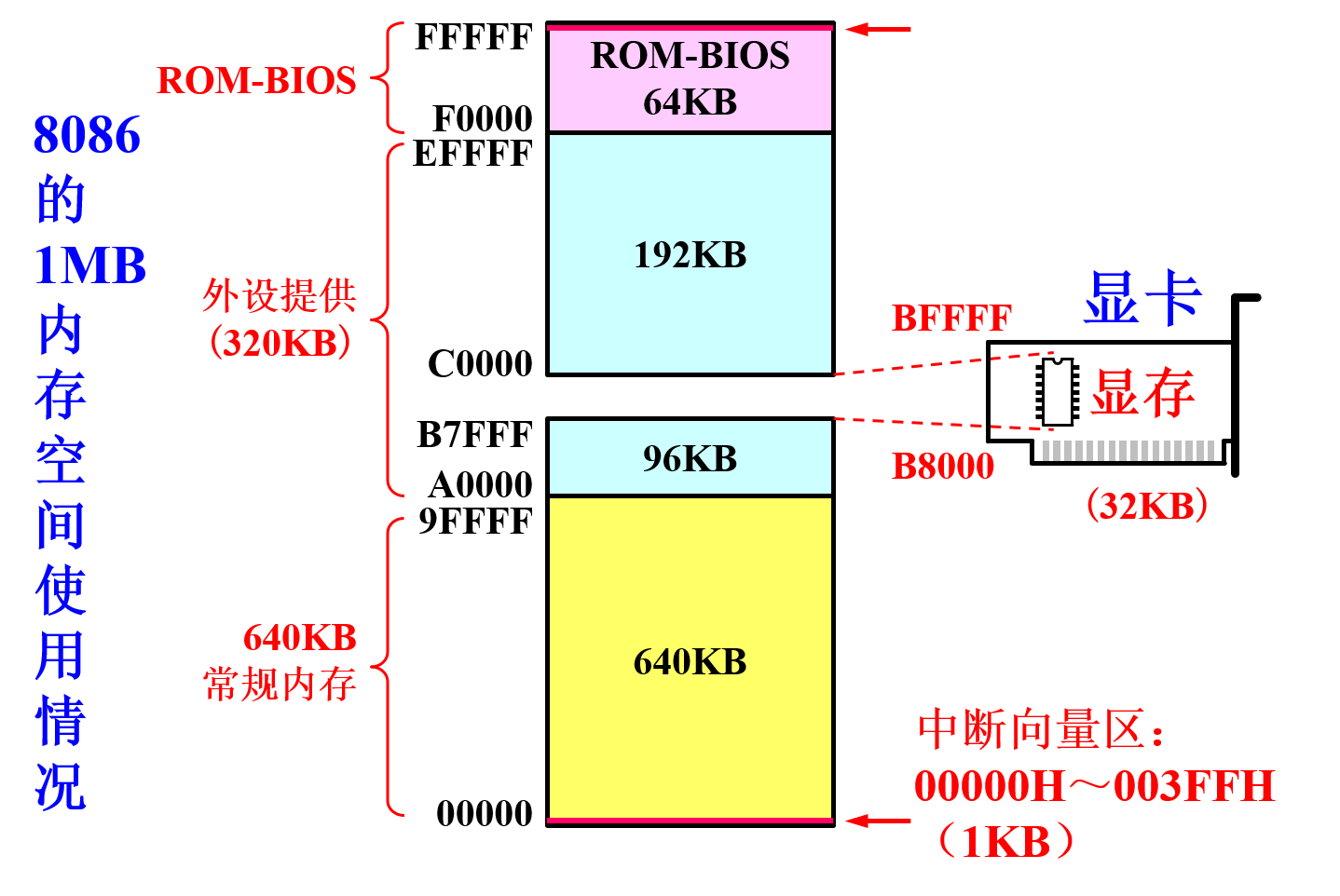
工作过程
应用程序->OS函数->BIOS功能->硬件
例如,在显示器上显示一个特定颜色字符串:
- 应用程序调用一个库函数向标准输出上写字符串。
- 库函数(层次3)调用一个操作系统函数,传递一个字符串指针。
- 操作系统函数(层次2)重复调用BIOS的某个功能,向它传递ASCII码及每个字符的颜色,操作系统调用另外一个BIOS功能将光标前进到屏幕的下一个字符位置。
- BIOS功能(层次1)接收每个字符,将其映射为特定的系统字体,然后把字符送至与视频控制卡相连的硬件端口。
- 视频控制卡(层次0)定时产生硬件信号给显示器以控制光栅扫描和象素显示。
8086 汇编程序设计
Hello World 程序
完整段定义的程序结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
stack segment stack
db 100 dup (?)
stack ends
data segment
message db 'Hello, world',0dh,0ah,'$'
data ends
code segment
assume cs:code,ds:data,ss:stack
start:
mov ax,data
mov ds,ax
mov ah,9
mov dx,offset message
int 21h
mov ah,4ch
int 21h
code ends
end start
其中:
- 完整段定义:
1 2 3
段名 SEGMENT [对齐方式] [组合方式] ['类'] 语句 段名 ENDS段名:标识段的名字,惟一的或已存在的。 对齐方式:可以是 BYTE、WORD、DWORD、PARA、PAGE。 组合方式:可以是 PRIVATE、PUBLIC、STACK、COMMON、MEMORY、AT地址。 类:用于标识特定类型段的名字,如CODE、STACK等。
- ASSUME伪指令:告诉汇编程序,哪一个段和哪一个段寄存器相对应,即某一段地址应放入哪一个段寄存器。
- 操作系统的装入程序在装入执行时,把CS初始化成正确的代码段地址,把SS初始化为正确的堆栈段地址,因此源程序中无再需初始化CS、SS。
- 装入程序已将DS寄存器留作它用,故在源程序中应有以下两条指令: MOV AX,DATA MOV DS,AX
- DOS环境下,汇编语言返回DOS: MOV AH,4CH INT 21H
简化段定义的程序结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
.model small,stdcall ;存储模型:小型
.stack 100 ;定义堆栈段及其大小
.data ;定义数据段
message db 'Hello, world',0dh,0ah,'$' ;数据声明
.code ;定义代码段
start: ;起始执行地址标号
mov ax,data ;数据段地址
mov ds,ax ;存入数据段寄存器
;具体程序代码
mov ah,9
mov dx,offset message
int 21h
mov ah,4ch
int 21h ;程序结束
end start
关键概念
- 汇编语言:用指令的助记符、符号地址、标号、伪指令等符号书写程序的语言。
- 汇编语言源程序:用汇编语言书写的程序。
- 汇编:把汇编语言源程序翻译成机器语言程序的过程。
- 汇编程序:完成汇编过程的系统程序。
- 语句格式:汇编语言语句的格式
…中的参数必需,即默认必需[…]中的参数可选{…|…}多选一(由|分割)
- 常数: 整数常量和字符串常量
- 伪指令:用来对汇编程序进行控制,以使程序中的数据实现条件转移、列表、存储空间分配等处理。其格式与汇编指令一样,但一般不产生目的代码。
- 运算符: 算术运算符等
- 源程序的结构: 代码结构
- 实地址模式/保护模式:实(地址)模式将整个物理内存看成分段的区域,程序代码和数据位于不同区域,系统程序和用户程序没有区别对待,而且每一个指针都是指向真实的物理地址;保护模式中物理内存地址不能直接被程序访问,程序内部的地址(虚拟地址)要由操作系统转化为物理地址去访问,程序对此一无所知。
- 大端/小端存储: 大端存储(常识)用于网络,有利于人看,如 5678H 表式存储为 5678H;小端存储(反常识)用于 intel 处理器,有利于电脑看,如 5678H 表式存储为 7856H
- 32位和16位:32位最先出现在80386处理器,16位最先出现在8086处理器(8086只支持实模式);从80386开始,cpu有三种工作方式:实模式,保护模式和虚拟8086模式。只有在刚刚启动的时候是实模式,等到操作系统运行起来以后就运行在保护模式。虚拟8086模式是运行在保护模式中的实模式,为了在32位保护模式下执行纯16位程序。它不是一个真正的CPU模式,还属于保护模式。CPU启动环境为16位实模式,之后可以切换到保护模式。但从保护模式无法切换回实模式
- ECX 和 CX:前者是后者的拓展,主要是在32位CPU中使用的(当然,由于 Intel 向下兼容,所以 64 位应该也可以)
MASM
MASM 4.00: 这是最先广泛使用的一个MASM版本,适用于DOS 下的汇编编程。它很精巧,但使用起来不是很智能化,需要用户自己一板一眼地写出所有的东西。很多教科书上讲的8086 汇编语法都是针对这个版本的,对程序员来说,它只比用Debug 方便一点点。MASM 5.00: MASM 5.00 比4.00 在速度上快了很多,并将段定义的伪指令简化为类似 .code 与.data 之类的定义方式,同时增加了对80386 处理器指令的支持,对4.00 版本的兼容性很好。MASM 5.10: 对程序员来说,这个版本最大的进步是增加了对@@标号的支持。这样,程序员可以不再为标号的起名花掉很多时间。另外,MASM 5.10 增加了对OS/2 1.x 的支持。MASM 5.10B: 1989 年推出,比上一个版本更稳定、更快,它是传统的DOS 汇编编译器中最完善的版本。MASM 6.00: 1992 年发布,有了很多的改进。编译器可以使用扩展内存,这样可以编译更大的文件,可执行文件名相应从Masm.exe 改为ML.exe。从这个版本开始可以在命令行上用*.asm同时编译多个源文件,源程序中数据结构的使用和命令行参数的语法也更像C 的风格。最大的改进之一是开始支持 .if/.endif 这样的高级语法,这样,使用复杂的条件分支时和用高级语言书写一样简单,可以做到几千行的代码中不定义一个标号;另外增加了invoke 伪指令来简化带参数的子程序调用。这两个改进使汇编代码的风格越来越像C,可读性和可维护性提高了很多。MASM 6.00A: 未发售的版本。MASM 6.00B: 最后一个支持OS/2 的MASM 版本,修正了上一版本中的一些错误。MASM 6.10: 修正了一些错误,同时增加了/Sc 选项,可以在产生的list 文件中列出每条指令使用的时钟周期数。MASM 6.10A: 1992 年发布,修正了一些内存管理方面的问题。MASM 6.11: 1993 年11 月发布,支持Windows NT,可以编写Win32 程序,同时支持Pentium 指令,但不支持MMX指令集。MASM 6.11C: 1994 年发布,增加了对Windows 95 VxD 的支持。MASM 6.12: 1997 年8 月发布,增加 .686,.686P,.MMX 声明和对相应指令的支持。MASM 6.13: 1997 年12 月发布,增加了 .K3D 声明,开始支持AMD 处理器的3D 指令。MASM 6.14: 这是一个很完善的版本,它在 .XMM中增加了对Pentium III的SIMD指令集的支持,相应增加了OWORD(16 字节)的变量类型。MASM 6.15: 2000 年4 月发布。
编译、链接和运行程序
过程
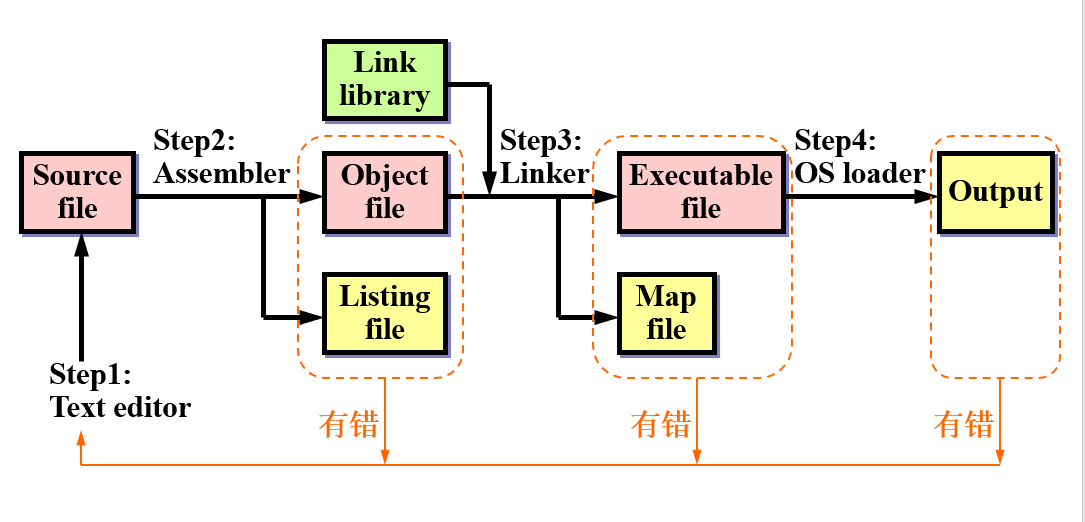
汇编程序做了什么?
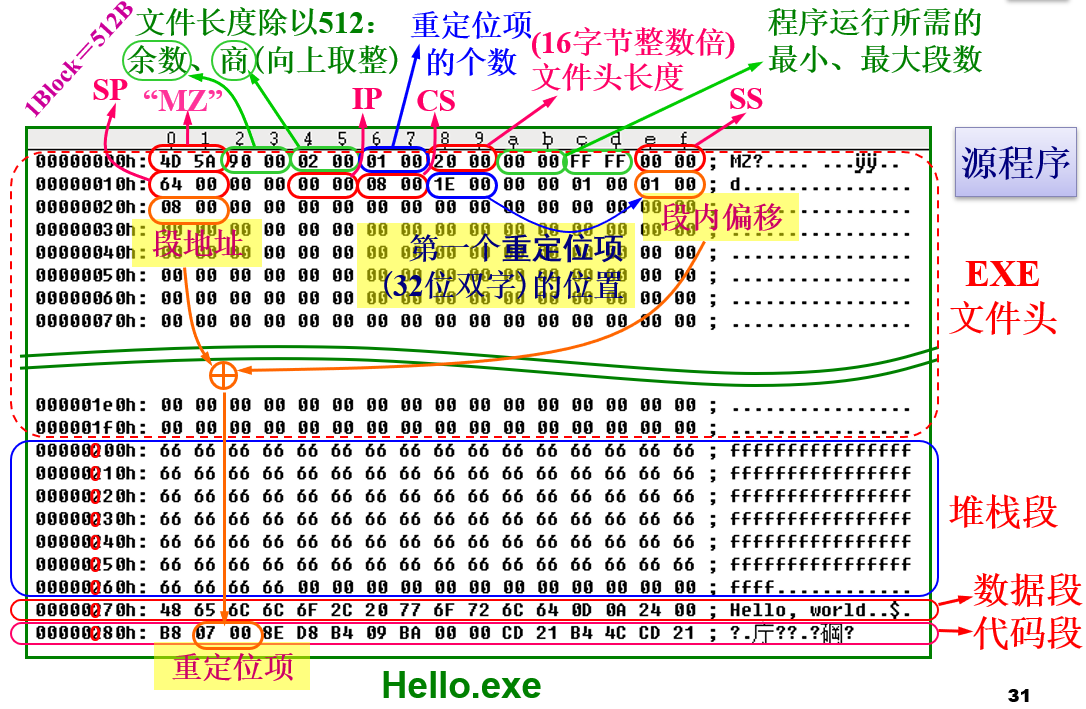 其中EXE的文件头
其中EXE的文件头MZ是Mark Zbikowski的缩写,Mark Zbikowski 曾是Microsoft 高级构架师和最早的计算机黑客之一,DOS 可执行文件格式的设计者。 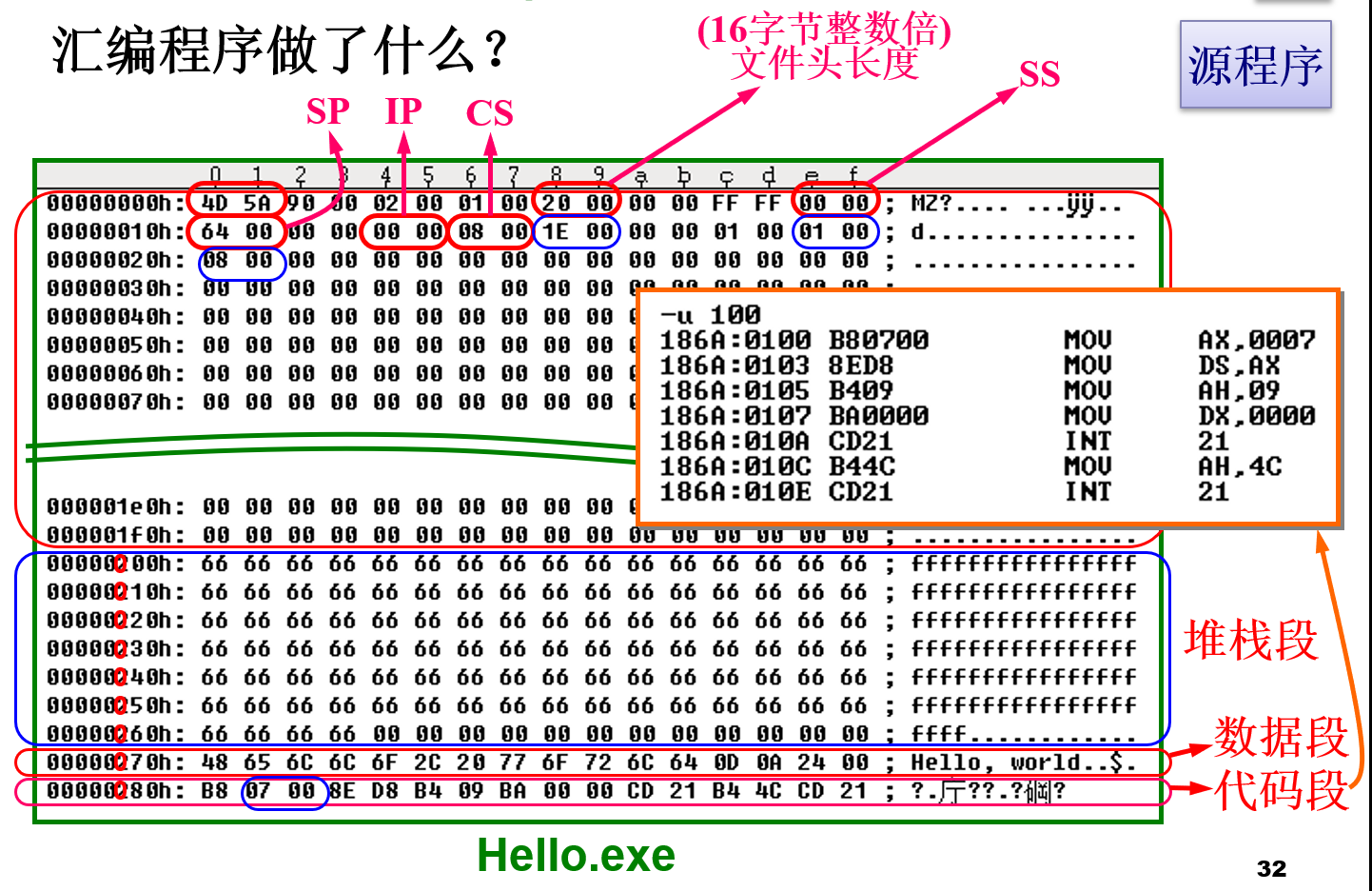
基本元素
…中的参数必需,即默认必需[…]中的参数可选{…|…}多选一(由|分割)
整数常量
1
[{+|-}]digits[radix]
digits是一个整数radix(基数后缀)可以是以下之一(大小写均可):h: 十六进制b: 二进制q/o: 八进制r: 编码实数d: 十进制
例如:
26 26d 11010011b 42q 42o 1Ah 0A3h
字符、字符串常量
1
2
3
4
5
6
7
'A'
"d"
'ABC'
"Goodnight, Gracie"
'4096'
"This isn't a test"
'Say "Goodnight," Gracie'
算术运算符
| 运算符 | 名称 | 优先级 |
() | 圆括号 | 1 |
+, - | 单目加、减 | 2 |
*, / | 乘、除 | 3 |
MOD | 取模 | 3 |
+, - | 加、减 | 4 |
保留字
保留字:有特殊含义,只能用于正确的上下文环境中
- 指令助记符,例如:
MOV,ADD,MUL - 伪指令,告诉
MASM如何编译程序,如:ASSUME,OFFSET,.data,.code,name PROC - 属性,为变量和操作数提供有关尺寸及使用方式信息,如:
BYTE,WORD - 运算符,用在常量表达式中,如:
+,-,*,/。 - 预定义符号,例如
@data,在编译时返回整数常量值。
标识符
标识符:程序员选择的名字,用来识别变量、常量、过程或代码标号。
- 可包含1~247个字符。
- 大小写不敏感。(汇编器加
-Cp参数则大小写敏感) - 第一个字符必须是字母(
A-Z和a-z)、下划线(_)、@、?或$,后续字符可以是数字。 - 不能与保留字相同。
- 尽量避免用
@和_作为第一个字符,因为它们即用于汇编器,也用于高级语言编译器。
指令
指令:程序被加载至内存开始运行后,由处理器执行的语句。
1
[标号:] 指令助记符 [操作数] [;注释]
例子:
1 2 3 4 5
;代码标号 target: mov ax,bx ... jmp target
1 2
;数据标号 first BYTE 10
数据定义
1
[名称] 类型 初始值[,初始值]…
其中类型可以为:
| 类型 | 用途 | 早期版本 |
|---|---|---|
| BYTE | 8位无符号整数 | DB |
| SBYTE | 8位有符号整数 | |
| WORD | 16位无符号整数(可在实模式下用作近指针) | DW |
| SWORD | 16位有符号整数 | |
| DWORD | 32位无符号整数(可在保护模式下用作近指针) | DD |
| SDWORD | 32位有符号整数 | |
| FWORD | 48位整数(可在保护模式下用作远指针) | |
| QWORD | 64位整数 | DQ |
| TBYTE | 80位整数 | DT |
| REAL4 | 32位IEEE短实数 | |
| REAL8 | 64位IEEE长实数 | |
| REAL10 | 80位IEEE扩展精度实数 |
例如:
1
2
3
4
5
6
7
8
9
.data
value1 BYTE 10h
value2 BYTE ?
list1 BYTE 10,20,30,40
BYTE 50,60,70,80
list2 BYTE 32,41h,00100010b,'a'
greeting BYTE "Good afternoon",0dh,0ah,0
array WORD 5 DUP(?) ;5个未初始化的值
value3 DWORD 12345678h
符号常量
符号常量:不占用任何实际的存储空间。
- 等号伪指令,例如:
1 2 3 4 5
COUNT = 500 ESC_key = 27 array COUNT DUP(0) mov cx,COUNT mov al,ESC_key
EQU伪指令TEXTEQU伪指令($ - array)伪指令,计算数组和字符串的大小,例:1 2 3 4 5 6 7 8
list1 BYTE 10,20,30,40 List1Size = ($ - list1) myString BYTE "This is a long string," BYTE " Containing any number" BYTE " of characters",0dh,0ah MyString_len = ($ - myString) list2 WORD 1000h,2000h,3000h,4000h List2Size = ($ - list2)/2
数据传送指令—— MOV 类指令
操作数类型
- 立即操作数(immediate)
imm: 8、16或32位立即数imm8: 8位立即数(字节)imm16: 16位立即数(字)imm32: 32位立即数(双字)
- 寄存器操作数(register)
reg: 任意的通用寄存器sreg: 16位段寄存器CS、DS、SS、ES、FS、GSr8: AH、AL、BH、BL、CH、CL、DH、DLr16: AX、BX、CX、DX、SI、DI、SP、BPr32: EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP
- 内存操作数(memory)
mem: 8、16或32位内存操作数
- 其它约定
r/m8: 8位操作数(8位通用寄存器或内存字节)r/m16: 16位操作数(16位通用寄存器或内存字)r/m32: 32位操作数(32位通用寄存器或内存双字)
直接内存操作数

MOV
1
2
3
4
5
6
7
mov destination,source
mov reg,reg
mov mem,reg
mov reg,mem
mov mem,imm
mov reg,imm
类似 C语言中destination=source
MOV指令需要遵循的规则:
- 两个操作数的尺寸必须一致。
- 两个操作数不能同时为内存操作数。
- 目的操作数不能是CS,EIP和IP。
- 立即数不能直接送至段寄存器。
- 段寄存器仅用于实地址模式(即80386中的保护模式下不行)下运行的程序。
- 内存之间的移动通过寄存器暂存。如:
1 2 3 4 5 6
.data var1 WORD ? var2 WORD ? .code mov ax,var1 mov var2,ax
MOVZX
move with zero-extend
1
2
3
4
movzx r32,r/m8
movzx r32,r/m16
movzx r16,r/m8
MOVSX
move with sign-extend
1
2
3
4
movsx r32,r/m8
movsx r32,r/m16
movsx r16,r/m8
XCHG
exchange data: 交换两个操作数的内容。
1
2
3
xchg reg,reg
xchg reg,mem
xchg mem,reg
加减法类指令
INC和DEC
- 含义:increment和decrement,加1、减1。
- 格式:
1 2
inc reg/mem dec reg/mem
- 例子:
1 2 3 4 5 6
.data myWord WORD 1000h .code inc myWord ; 1001h mov bx,myWord dec bx ; 1000h
- 影响的标志位:INC和DEC指令不影响进位标志
ADD
- 含义:将同尺寸的源操作数和目的操作数相加,结果在目的操作数中(不改变源操作数)。
- 格式:与MOV指令相同。
1
add 目的操作数,源操作数
- 例:
1 2 3 4 5 6
.data var1 DWORD 10000h var2 DWORD 20000h .code mov eax,var1 add eax,var2 ; 30000h
SUB
- 含义:将源操作数从目的操作数中减掉,结果在目的操作数中(不改变源操作数)。
- 格式:与MOV、ADD指令相同。
1
sub 目的操作数,源操作数
- 例:
1 2 3 4 5 6 7
.data var1 DWORD 30000h var2 DWORD 10000h .code mov eax,var1 sub eax,var2 ; 20000h
- 影响的标志位:CF、ZF、SF、OF、AF、PF
NEG
- 含义:negate,求负。将操作数按位取反、末位加1。
- 格式:
1 2
neg reg neg mem
- 影响的标志位:CF、ZF、SF、OF、AF、PF
标志位
- 零标志和符号标志
- 进位标志(无符号算术运算):INC和DEC指令不影响进位标志。
- 溢出标志(有符号算术运算)
1
OF=C𝑛⊕C(𝑛−1)
其中,Cn为符号位产生的进位,即标志位CF; Cn-1为最高有效位向符号位产生的进位。
例子程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
.386
.MODEL flat, stdcall
.STACK 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
Rval SDWORD ?
Xval SDWORD 26
Yval SDWORD 30
Zval SDWORD 40
.code
main PROC
mov ax,1000h ; INC and DEC
inc ax ; 1001h
dec ax ; 1000h
; Expression: Rval = -Xval + (Yval - Zval)
mov eax,Xval
neg eax ; -26
mov ebx,Yval
sub ebx,Zval ; -10
add eax,ebx
mov Rval,eax ; -36
; Zero flag example:
mov cx,1
sub cx,1 ; ZF = 1
mov ax,0FFFFh
inc ax ; ZF = 1
; Sign flag example:
mov cx,0
sub cx,1 ; SF = 1
mov ax,7FFFh
add ax,2 ; SF = 1
; Carry flag example:
mov al,0FFh
add al,1 ; CF = 1, AL = 00
; Overflow flag example:
mov al,+127
add al,1 ; OF = 1
mov al,-128
sub al,1 ; OF = 1
INVOKE ExitProcess,0
main ENDP
END main
和数据相关的操作符
OFFSET
- OFFSET 操作符返回数据标号的偏移地址(标号距数据段开始的距离,以字节为单位)。
- 保护模式下偏移总是32位的。
- 实模式下偏移只有16位。
- 可与直接偏移操作数联合使用
例如(假设bVal位于00303000h处):
1
2
3
4
5
6
7
8
9
10
11
12
13
.data
bVal BYTE ?
wVal WORD ?
dVal1 DWORD ?
dVal2 DWORD ?
.code
……
mov esi,OFFSET bVal ; ESI = 00303000
mov esi,OFFSET wVal ; ESI = 00303001
mov esi,OFFSET dVal1 ; ESI = 00303003
mov esi,OFFSET dVal2 ; ESI = 00303007
mov esi,OFFSET bVal + 1
……
PTR
用来重载操作数的默认尺寸。
必须和以下标准数据类型联合使用:BYTE,SBYTE,WORD,SWORD,DWORD,SDWORD,FWORD,QWORD,TBYTE
例如:
1
2
3
4
5
6
7
.data
myDouble DWORD 12345678h
.code
mov ax, myDouble ; 错误
mov ax, WORD PTR myDouble ; ax = 5678h
mov ax, WORD PTR [myDouble+2] ; ax = 1234h
mov bl, BYTE PTR myDouble ; bl = 78h
TYPE
返回按字节计算的变量的单个元素的大小。 例如如下代码:
1
2
3
4
5
.data
var1 BYTE ?
var2 WORD ?
var3 DWORD ?
var4 QWORD ?
则有:
| 表达式 | 值 |
| TYPE var1 | 1 |
| TYPE var2 | 2 |
| TYPE var3 | 4 |
| TYPE var4 | 8 |
LENGTHOF
计算数组中元素的个数。例如:
1
2
3
4
5
6
.data
byte1 BYTE 10,20,30
array1 WORD 30 DUP(?),0,0
array2 WORD 5 DUP(3 DUP(?))
arrar3 DWORD 1,2,3,4
digitStr BYTE "12345678",0
则有:
| 表达式 | 值 |
| LENGTHOF byte1 | 3 |
| LENGTHOF array1 | 30+2 |
| LENGTHOF array2 | 5×3 |
| LENGTHOF array3 | 4 |
| LENGTHOF digitStr | 9 |
注意如下代码:
1
2
3
4
5
6
7
8
pitches WORD 0960H,0960H,0960H,0960H,0960H,0960H,0BB8H,0960H,0834H,0960H
WORD 0BB8H,0CE4H,0BB8H,0960H,0960H,0BB8H,0960H,0BB8H,0CE4H,0E10H
WORD 0BB8H,0CE4H,0BB8H,0BB8H,0CE4H,1068H,0E10H,0CE4H,0834H,0834H
WORD 0960H,0BB8H,0834H,0960H,0960H,0BB8H,0CE4H,0BB8H,0960H,0960H
WORD 0BB8H,0CE4H,0BB8H,0960H,0BB8H,0CE4H,0BB8H,1068H,0E10H,0CE4H
WORD 0BB8H,0E10H
pitches_len=( $ - pitches)/2 ; =52,即正确的
pitches_len=LENGTHOF pitches ; =10,即错误的
SIZEOF
SIZEOF返回值=LENGTHOF返回值×TYPE返回值。例如下代码:
1
2
.data
intArray WORD 32 DUP(0)
则有:
| 表达式 | 值 |
| TYPE intArray | 2 |
| LENGTHOF intArray | 32 |
| SIZEOF intArray | 64 |
间接寻址
间接操作数(寄存器间接寻址)
用寄存器作为指针,通过改变指针寄存器的值来访问数组中的不同元素,这种寻址方式称为寄存器间接寻址,存放地址的寄存器称为间接操作数
间接操作数只能用SI,DI,BX,BP。通常尽量避免使用BP(BP常用来寻址堆栈而不是数据段)(32位汇编,即保护模式中可以是任何用方括号括起来的32位通用寄存器(EAX,EBX,ECX,EDX,ESI,EDI,EBP、ESP)。例如:
1
2
3
4
5
6
.data
val1 BYTE 10h
.code
main proc
mov si,OFFSET val1
mov AL,[si] ;AL=10h
PTR与间接操作数的联合使用例:
1
2
inc [esi] ; error: operand must have size
inc BYTE PTR [esi]
变址操作数(寄存器相对寻址)
例(32位):
1
2
3
4
5
6
7
8
9
10
.data
arrayB BYTE 10h,20h,30h
.code
mov esi,0
mov al,[arrayB + esi] ; AL = 10h
mov al,arrayB[esi] ; 同上,另一种格式
mov esi,OFFSET arrayB
mov al,[esi] ; AL = 10h
mov al,[esi+1] ; AL = 20h
mov al,[esi+2] ; AL = 30h
实模式(即16位汇编)下只能使用SI,DI,BX,BP寄存器。(尽量避免使用BP寄存器)
JMP和LOOP指令
控制转移(跳转)或分支是一种改变程序执行顺序的方法。 控制转移可分为两种: 无条件转移:以JMP指令为例 条件转移:以LOOP指令为例
JMP
例:创建一个循环
1
2
3
4
5
top:
.
.
.
jmp top ; repeat the endless loop
LOOP
格式:
1
LOOP 目的地址
LOOP指令的执行过程:ECX-=1; ECX=0?退出循环:跳转到目的地址; ECX-=1; ....
- 在实地址模式下,用做默认循环计数器的是CX而不是ECX。如:
1 2 3 4
mov ax,0 mov cx,5 L1: inc ax loop L1循环结束时,AX=5 ECX=0
- 在 32 位 CPU 中的任何模式下,LOOPD指令都使用ECX作为循环计数器;LOOPW都使用CX作为循环计数器。
- 循环的目的地址与当前地址只能在相距-128到+127字节的范围之内。机器指令平均3字节左右,因此一个循环平均最多只能包含大约42条指令。
- 循环可以嵌套。如:
1 2 3 4 5 6 7 8 9 10 11
.data count DWORD ? .code mov ecx,100 L1: mov count,ecx mov ecx,20 L2: . . loop L2 mov ecx,count loop L1
过程—— PROC 相关指令
与外部库链接
链接库:包含已经编译成机器码的过程的文件。
编译源文件->产生目标文件->插入到库中
链接库如何工作?假设程序要调用Irvine32.inc文件中的名为WriteString的过程在控制台上显示字符串,则:
- 程序中要用 PROTO 伪指令声明要调用的程序。
Irvine32.inc中包含语句WriteString PROTO - 用一条 CALL 指令执行 WriteString 过程:
call WriteString - 当程序被编译时,编译器为 CALL 指令的目标地址留出空白,该空白将由链接器填充。
- 链接器在链接库中查找WriteString这个名字,从库中把合适的机器指令拷贝到程序的可执行文件中,并把WriteString的地址插入到CALL指令中。
链接器的命令行选项 例:
1
Link32 /subsystem:windows HelloWin.obj user32.lib kernel32.lib
链接时引入user32.lib和kernel32.lib文件->运行时就会引用user32.dll和kernel32.dll
kernel32.lib可以在Microsoft Windows平台软件开发包(platform SDK)中找到,它包含了存储在另一个文件 —— kernel32.dll 中的操作系统函数的链接信息。
存在的问题:
.inc、.obj、.dll文件的作用与联系?
经典例子
整数数组求和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
; This program sums an array of words. (SumArray.asm)
.386
.MODEL flat, stdcall
.STACK 4096
ExitProcess PROTO,dwExitCode:DWORD
.data
intarray WORD 100h,200h,300h,400h
.code
main PROC
mov edi,OFFSET intarray ; address of intarray
mov ecx,LENGTHOF intarray ; loop counter
mov ax,0 ; zero the accumulator
L1:
add ax,[edi] ; add an integer
add edi,TYPE intarray ; point to next integer
loop L1 ; repeat until ECX = 0
INVOKE ExitProcess,0
main ENDP
END main
拷贝字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
TITLE Copying a String (CopyStr.asm)
; This program copies a string.
INCLUDE Irvine32.inc
.data
source BYTE "This is the source string",0
target BYTE SIZEOF source DUP(0),0
.code
main PROC
mov esi,0 ; index register
mov ecx,SIZEOF source ; loop counter
L1:
mov al,source[esi] ; get a character from source
mov target[esi],al ; store it in the target
inc esi ; move to next character
loop L1 ; repeat for entire string
INVOKE ExitProcess,0
main ENDP
END main
链接
缩略语
- AF: Auxiliary carry Flag(辅助进位标志)
- AH: Accumulator register High(寄存器 A 高位)
- AL: Accumulator register Low(寄存器 A 低位)
- AMD: Advanced Micro Devices
- ASCII: American Standard Code for Information Interchange
- AT: Advanced Technology
- AX: Accumulator register (寄存器 A)
- BH: Base register High(寄存器 B 高位)
- BIOS: Basic Input Output System
- BIU: Bus Interface Unit(总线接口单元)
- BL: Base register Low(寄存器 B 低位)
- BP: Base Pointer
- BX: Base register(寄存器 B)
- CF: Carry Flag(进位标志)
- CH: Count register High(寄存器 C 高位)
- CL: Count register Low(寄存器 C 低位)
- CPU: Central Processing Unit
- CS: Code Segment(代码段)
- CX: Count register(寄存器 C)
- DD: Define Dword
- DEC: DECrement(递减)
- DH: Data register High(寄存器 D 高位)
- DI: Destination Index
- DL: Data register Low(寄存器 D 低位)
- DOS: Disk Operating System
- DQ: Define QWORD
- DS: Data Segment
- DT: Define TBYTE
- DUP: DUPlicate
- DW: Define WORD
- DWORD: Double WORD
- DX: Data register(寄存器 D)
- EAX: Extented AX
- EBP: Extented BP
- EBX: Extented BX
- ECX: Extented CX
- EDI: Extented DI
- EDX: Extented DX
- EIP: Extented IP
- ENDP: END Process
- ENDS: END Segment
- EQU: EQUal
- ES: Extra Segment
- ESI: Extented SI
- ESP: Extented SP
- EU: Execute Unit
- EXE: EXEcute
- FS: File System
- FWORD: Far WORD
- IA: Intel Architecture
- IEEE: Institute of Electrical and Electronics Engineers
- INC: INCrement
- INT: INTerrupt
- IO: Input Output
- IP: Instruction Pointer
- JMP: JuMP
- KB: Kilobyte
- LOOPD: LOOP DWORD
- LOOPW: LOOP WORD
- MB: Megabyte
- MMX: Multi-Media Extensions
- MOV: MOVe
- MOVSX: MOVe with Sign-eXtend
- MOVZX: MOVe with Zero-eXtend
- MUL: MULtiplication
- MZ: Mark Zbikowski
- NEG: NEGative
- NT: New Technology
- NT: Windows New Technology (Windows NT)
- OF: Overflow Flag
- OOP: Object-Oriented Programming
- OS: Operating System
- OV: OVerflow
- PARA: PARAgraph
- PF: Parity Flag
- PROC: PROCess
- PROTO: PROTOtype
- PTR: PoinTeR
- QWORD: Quadruple WORD
- SBYTE: Sign BYTE
- SDK: Software Development Kit
- SDWORD: Sign DWORD
- SF: Sign Flag
- SI: Source Index
- SIMD: Single Instruction, Multiple Data
- SP: Stack Pointer
- SS: Stack Segment
- SUB: SUBtract
- SWORD: Sign WORD
- TBYTE: TB
- XCHG: eXCHanGe data
- ZF: Zero Flag *[AF]: Auxiliary carry Flag(辅助进位标志) *[AH]: Accumulator register High(寄存器 A 高位) *[AL]: Accumulator register Low(寄存器 A 低位) *[AMD]: Advanced Micro Devices *[ASCII]: American Standard Code for Information Interchange *[AT]: Advanced Technology *[AX]: Accumulator register (寄存器 A) *[BH]: Base register High(寄存器 B 高位) *[BIOS]: Basic Input Output System *[BIU]: Bus Interface Unit(总线接口单元) *[BL]: Base register Low(寄存器 B 低位) *[BP]: Base Pointer *[BX]: Base register(寄存器 B) *[CF]: Carry Flag(进位标志) *[CH]: Count register High(寄存器 C 高位) *[CL]: Count register Low(寄存器 C 低位) *[CPU]: Central Processing Unit *[CS]: Code Segment(代码段) *[CX]: Count register(寄存器 C) *[DD]: Define Dword *[DEC]: DECrement(递减) *[DH]: Data register High(寄存器 D 高位) *[DI]: Destination Index *[DL]: Data register Low(寄存器 D 低位) *[DOS]: Disk Operating System *[DQ]: Define QWORD *[DS]: Data Segment *[DT]: Define TBYTE *[DUP]: DUPlicate *[DW]: Define WORD *[DWORD]: Double WORD *[DX]: Data register(寄存器 D) *[EAX]: Extented AX *[EBP]: Extented BP *[EBX]: Extented BX *[ECX]: Extented CX *[EDI]: Extented DI *[EDX]: Extented DX *[EIP]: Extented IP *[ENDP]: END Process *[ENDS]: END Segment *[EQU]: EQUal *[ES]: Extra Segment *[ESI]: Extented SI *[ESP]: Extented SP *[EU]: Execute Unit *[EXE]: EXEcute *[FS]: File System *[FWORD]: Far WORD *[IA]: Intel Architecture *[IEEE]: Institute of Electrical and Electronics Engineers *[INC]: INCrement *[INT]: INTerrupt *[IO]: Input Output *[IP]: Instruction Pointer *[JMP]: JuMP *[KB]: Kilobyte *[LOOPD]: LOOP DWORD *[LOOPW]: LOOP WORD *[MB]: Megabyte *[MMX]: Multi-Media Extensions *[MOV]: MOVe *[MOVSX]: MOVe with Sign-eXtend *[MOVZX]: MOVe with Zero-eXtend *[MUL]: MULtiplication *[MZ]: Mark Zbikowski *[NEG]: NEGative *[NT]: New Technology *[NT]: Windows New Technology (Windows NT) *[OF]: Overflow Flag *[OOP]: Object-Oriented Programming *[OS]: Operating System *[OV]: OVerflow *[PARA]: PARAgraph *[PF]: Parity Flag *[PROC]: PROCess *[PROTO]: PROTOtype *[PTR]: PoinTeR *[QWORD]: Quadruple WORD *[SBYTE]: Sign BYTE *[SDK]: Software Development Kit *[SDWORD]: Sign DWORD *[SF]: Sign Flag *[SI]: Source Index *[SIMD]: Single Instruction, Multiple Data *[SP]: Stack Pointer *[SS]: Stack Segment *[SUB]: SUBtract *[SWORD]: Sign WORD *[TBYTE]: TB *[XCHG]: eXCHanGe data *[ZF]: Zero Flag