五笔输入法
引言
当我刚接触电脑的时候,用的是拼音输入法(全拼),一开始没觉得有什么问题,直到用过不同平台的拼音输入法后,发现输入同样的编码,出来的候选字顺序却不相同,这大大降低了我的输入效率,于是我开始寻找编码固定的输入法方案,最终发现了五笔。五笔除了解决了前述问题之外,还解决了全拼输入法重码率高的问题。
五笔字型输入法,简称五笔、又称王码,是王永民在1983年8月发明的一种汉字输入法。中文输入法的编码方案很多,但基本依据都是汉字的读音和字形两种属性。五笔字型完全依据笔画和字形特征对汉字进行编码,是典型的形码输入法。
五笔字型输入法主要用于使用简体中文的中国大陆,过去,拼音输入法严重重码,五笔输入是最方便的选择。但随着智能拼音的兴起,以及拼音输入法天然的“零训练”特性(对于掌握汉语拼音的用户,拼音输入法几乎不必专门练习),需要专门训练才能熟练应用的五笔输入法在应用人数上已经不具备优势。但极低的重码率,保证了五笔的输入速度仍遥遥领先,因此大多数专业打字员至今(何时?)仍然习惯使用五笔字型。
——引用自五笔字型输入法 - 维基百科
概述
五笔,顾名思义,由汉字最基本的五个笔画(横(一)、竖(丨)、撇(丿)、捺(丶)、折(乙))为基础,延伸出字根,即汉字的组成部分,如木、工、口、大、氵、又等。比如“汉”由“氵”和“又”组成,则“氵”和“又”就是其字根。
可以说汉字就是由字根组成的,而字根是比较多的,86 版就有 234 个字根,而键盘上却只有 26 个字母键,那么要通过这些字母按键得到字根,进一步再得到汉字,就必然需要将一个字母键对应到多个字根,如何对应呢?一个简单的思路是平均分配,即一个按键对应 234/26=9 个字根,但这样一来,学习和记忆起来会非常困难。
为了解决学习和记忆困难的问题,创始人王永民先生将五个笔画映射到键盘上的五个区域:横区、竖区、撇区、捺区、折区,每个区域只有 5 个按键,一共用到了 5*5 = 25 个按键,留下一个按键 z 用作其他功能。为了方便记忆,并没有将字根平均分布到每个按键上,而是按照一定的规律进行分布。这样一来,我们容易发现最多按 4 个键,就必然能输出任意汉字,因为按 4 个按键已经有 25^4 = 390625 种可能,即可对应 39 万个汉字,而我们常用的汉字仅仅几千个,远远达不到 39 万这个数量级。
完成字根和按键间的映射工作后,就能通过按键得到字根,进而组合多个按键得到汉字,比如假设我要输入“输”字,可将拆分成“车”、“人”、“一”、“月”、“刂”几个字根,我们只需要输入这些字根对应的按键即可,事实上,输入前三个就出来了。
由此可见,使用五笔输入一个汉字的步骤如下:
- 拆出它的组成部分,即字根
- 找出字根对应的按键
- 按书写顺序敲击对应的按键
在深入细节前,让我们先简要了解下五笔的历史和延伸出来的三个版本:86 版、98 版、新世纪版。
历史与版本
五笔历史悠久,从 1983 年出现,经过不断完善,到 1986 年出第一个版本,即“86 版”,而后 1998 出第二个版本,即“98 版”,再到 2008 年出第三个版本,即“新世纪版”,到如今 2025 年已经有 42 年了,但其依然经久不衰,足见其生命力强大。
这三个版本中:86 版是使用最广泛的版本,使用 234 个字根,可处理 GB 2312-80 汉字集中的 6763 个汉字,该版本的专利权已过,其编码进入了开源领域,其他人可以自由使用和修改;98 版是一种改进型的方案,对编码的科学性做了优化,并拓展汉字数量到 21003 个,其中引入了繁体字;新世纪版采用了新设计的字根体系,更加符合分区划位规律,从而更加易记和实用,可处理 GB 18030-2000 汉字集中的 27533 个简繁字。
由于我最初学习的就是 86 版,所以现在用的也是 86 版,且我使用的 Rime 输入法官方目前只有 86 版的字典。后面也会以 86 版五笔为主进行讲解。
下面我们开始梳理五笔的细节,让我们先从字根开始。
字根
86 版五笔使用 234 个字根,这些字根要映射到标准键盘的 26 个字母按键上,为了方便记忆,五笔创始人根据这些字根的首笔画进行分区,而笔画主要有 5 种——横、竖、撇、捺、折,故分为相应的 5 个区:横区、竖区、撇区、捺区、折区,为了方便说明,将它们分别编号为:1、2、3、4、5, 即 1 号区对应横区,2 号区对应竖区,以此类推。
每个区域里有 5 个按键,为了方便定位到具体的按键,对这 5 个按键也从 1 到 5 进行编号,这 5 个编号也对应到 5 个笔画,不过代表的不是字根的首笔画,而是第二笔画,比如“王”就是首笔画和第二笔画都是横,所以就是 1 号区 1 号位的键,即 G 键,又比如“大”这一字根首笔画是横,第二笔画是撇,所以对应 1 号区 3 号位的键,即 D 键,以此类推。
字根在键盘上的分布如下图所示:
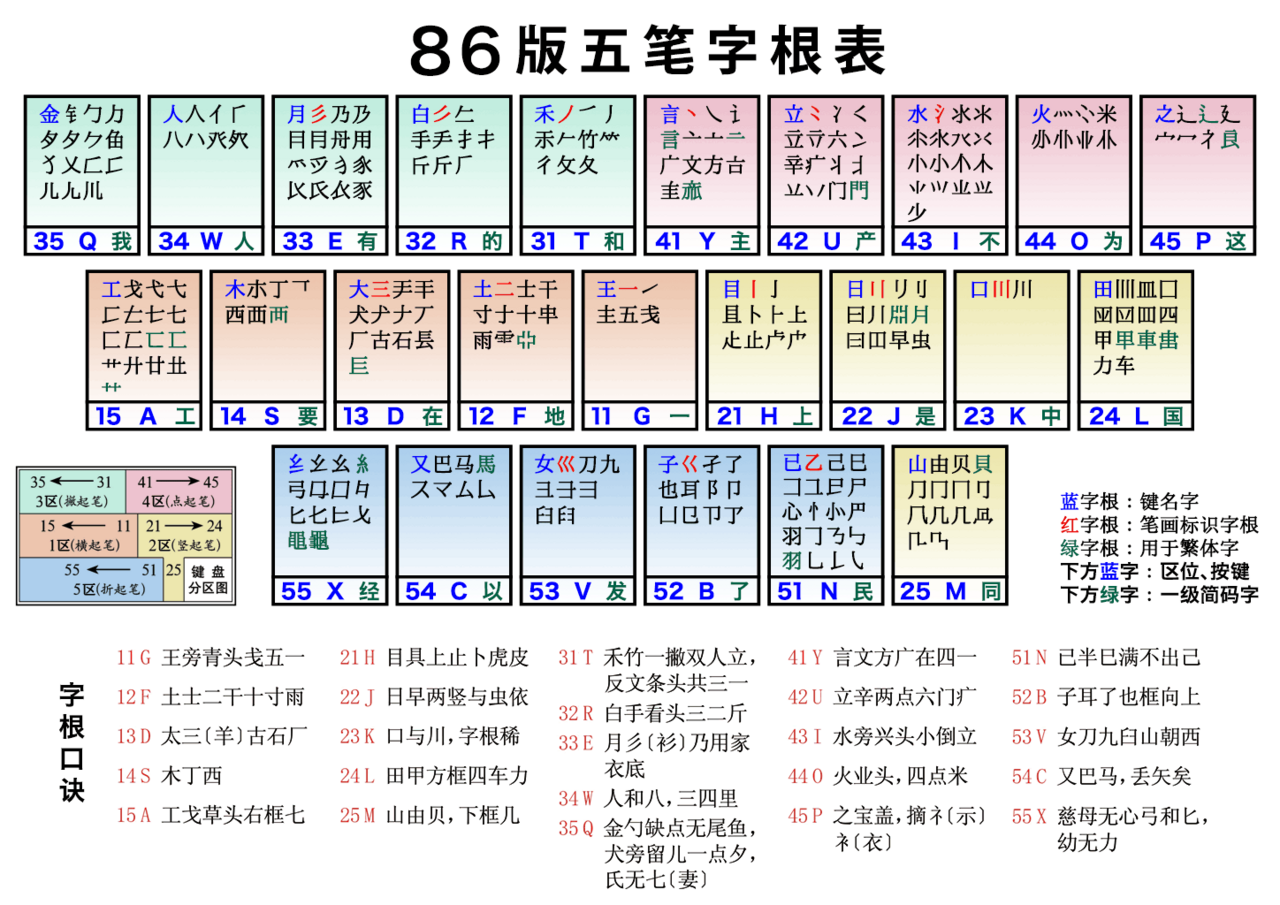
这个图的信息量非常大,且有良好的注解。让我们一起来仔细看一下。
首先我们需要注意到的是整体上有五个颜色的区域,它们分别对应前述的五个区(横、竖、撇、捺、折),左侧有个“键盘分区图”可以先看一下:中间那排左边的按键是 1 区,即横区;右边是 2 区,即竖区,需要注意的是,下方那排右边的 M 键也是属于竖区;上左是 3 区,即撇区;上右是 4 区,即捺区;下左是 5 区,即折区。这个“键盘分区图”还指示了定位信息,即如何定位到具体的按键:从中间往两边散开进一步从 1 开始编号从而定位,比如一号区一号位对应的就是 G 键,简记为 11 键, 一号区二号位对应的就是 F 键,简记为 12 键等等。
其次,我们应注意到每个键中都有大量字根,且数量不一,比如 11 键(G)只有 5 个字根,而 35 键(Q)有 15 个字根,这是由于为了方便记忆,将相关的字根放在了一个按键上。其中每个按键最左上角的字根被加粗为蓝色,这是键名。为什么要有这样的键名呢?平时我们使用英文字母表达键名,如 A 键、B 键等,但对于不会英文的人而言,这些难以阅读和书写,所以需要有中文的键名。那么这些键名是如何从众多字根中选出来的呢?首先它得是一个汉字组成部分,这是作为字根的基本要求,其次它本身是一个汉字,这样才易读,然后它最好具有某种意义上的代表性(比如能明确标识它的位置),例如“禾”这个键名就很好,它的首笔画是撇,第二笔画是横,所以理论上应在 3 号区 1 号位的按键上,而它确实符合这个理论。
此外,我们还会注意到每个按键最下方有一行特别的内容,里面可划分为三个部分:数字、字母、汉字,这三部分分别是什么意思呢?数字即前述的位置编号,如 35 即 3 号区 1 号位;字母即对应的字母按键;汉字则比较特殊,它代表按该键一次即可按出的汉字,这样的字通常是常用字,这也是为了提高输入效率。
取码原理
对于某个汉字,如何确定它的编码,即需要依次敲击哪些按键?我们已经知道五笔的基本思想是以五个笔画为基础,通过笔画构造字根,通过字根构造汉字,所以对于此问题,我们只需要反过来,对于给出的汉字拆解出字根,再按顺序敲击这些字根对应的按键,即可完成该汉字的录入。所谓取码原理,即如何将任意一个汉字映射到对应的按键顺序,这里有两个要点:按哪些键?以什么顺序按这些键?下面我们先讨论如何录入一个汉字,再讨论如何录入一个词组。
单字
单字是最基本的,掌握输入单字的方法即可在理论上输入任意多的汉字(一个一个地敲🤣)。
首先需要明确的是:五笔中最多敲击 4 个按键便可唯一确定一个汉字。注意这里的“最多”,那么最少呢?最少只敲击一个按键即可得到一个汉字,类似地,敲击 2 个按键和 3 个按键能否得到一个汉字呢?答案也是能。汉字的完整编码(通常为 4 码)称之为全码,其余称之为简码。简码,顾名思义,就是敲击尽可能少的按键即可得到相应汉字的编码,敲击 1 个按键的称之为一级简码,敲击 2 个按键的称之为二级简码,敲击 3 个按键的称之为三级简码。需要注意的是,一级、二级、三级简码对应的汉字也有全码,比如“我”这个汉字,它可以直接通过 Q 键敲出,也可通过全码 TRNT 敲出,以及“物”这个字,其二级简码为 TR,全码为 TRQR。
由于全码是核心,所以下面先讲全码。
全码
全码指的是一个汉字的完整编码,即按照五笔字型的拆分规则,输入该字所有应输入的字根,而不是用简码或只输入部分字根。全码无疑是非常之多的,我们只能讲解其规律,而非罗列所有。如前所述,使用五笔输入一个汉字的步骤如下:
- 拆出它的组成部分,即字根
- 找出字根对应的按键
- 按书写顺序敲击对应的按键
容易发现,对于步骤 1 和 3 均不一定有唯一的结果。比如对于“香”字而言,至少有两种拆解方式:“禾+日”和“丿+木+日”,对此我们该选哪种呢?又比如对于“书”字,可以先写折也可以先写竖,我们又该选择哪种呢?诸如此类的问题还有很多,所以我们需要一个判定优先级的规则,五笔中这样的规则主要包括:
- 书写顺序:优先采用标准的书写顺序。比如对于前面的“书”字,应先写折后写竖。
- 能散不连:能分开就不要连着。比如对于“国”字,应拆分为“口+王+丶”而非“门+王+丶+一”。
- 兼顾直观:这个比较抽象,只能自己悟,或者凭感觉,甚至找不到一个合适的例子进行说明。
- 能连不交:相连和相交相比,相连优先级更高。比如对于“于”字,应拆分为“一+十”而非“二+亅”。
- 取大优先:优先采用笔画尽可能多的字根,即更“大”的字根。比如对于前述的“香”字,应拆分为“禾+日”而非“丿+木+日”
至于这些规则谁的优先级更高就不好说了,需要视情况而定。
除了前述的优先级问题,全码还有个基本的问题:对于刚好由 4 个字根组成的词,其全码是容易得出的,但对于小于 4 个或大于 4 个的呢?比如对于“余”字,其拆解出的字根为“人+禾”,只有 2 个字根,打完这两个字根发现并没有出来“余”字,怎么办呢?这时应该加上识别码 U;又如对于“键”字,其拆解出的字根为“钅+彐+二+丨+廴”,共有 5 个字根,这时应该只取前三个和最后一个,即“钅+彐+二+廴”,对应按键 QVFP。
简单来说,对于大于等于 4个字根的汉字,采用“前 3 个字根 + 最后一个字根”的方式,对于小于 4 个字根的汉字,需要在打完所有的字根后添加一个识别码。理论上来说,识别码是可以不加的,加它是为了降低重码率,进一步提高效率。因此,如果某个字不需要加识别码也能打出首选,那么就不要加。
那么识别码是如何判定的呢?答案是根据“末笔画所在区域”和“字型结构”确定。比如对于前述的“余”字,其末笔画为捺,故识别码应在捺区(3 号区),具体是捺区的哪一个键呢?看该字的字型结构,字型结构有三种:左右型、上下型、杂合型,分别对应位号 1、2、3。而“余”的字型结构为上下结构,故对应位号 2, 因此,其识别码位于 3 号区 2 号位,即 U 键(键名为“立”)。下表罗列了此规则的各种情况:
| 末笔\字型 | 左右 1 | 上下 2 | 杂合 3 |
|---|---|---|---|
| 横 1 | 11 (G) | 12 (F) | 13 (D) |
| 坚 2 | 21 (H) | 22 (J) | 23 (K) |
| 撇 3 | 31 (T) | 32 (R) | 33 (E) |
| 捺 4 | 41 (Y) | 42 (U) | 43 (I) |
| 折 5 | 51 (N) | 52 (B) | 53 (V) |
以上是常规字,但有些字比较特殊,主要包括笔画、键名和字根(部分字根也称之为偏旁部首),所谓键名,就是前述字根章节中图片里每个按键左上角的字根,如“金”、“人”、“月”、“白”、“禾”等。
对于笔画,主要是指横(一)、竖(丨)、撇(丿)、捺(丶)、折(乙),其输入方法为“所在区域 1 号按键*2 + LL”。比如对于竖(丨),其编码为 HHLL。
对于键名,其输入方法为:对应按键*4, 即按 4 次对应按键。比如“金”对应的编码为 QQQQ,“禾”对应的编码为 TTTT。
对于字根,其输入方法为:键名代码 + 首笔代码 + 次笔代码 + 末笔代码(如果该字根只有两笔画,则补空格键结束),其中部分字根为偏旁。例如“钅”的编码为 QTGN(金 + 丿 + 一 + 乙)。在部分五笔输入法中,可使用 ZZPP 或 /PP 得到所有偏旁的候选词。
一级简码
一级简码是指一次按键即可敲出的汉字的编码,所以只有 25 个。前面字根一节中我们提到了图中每个按键下方有一行特殊的内容,包括三个部分:数字+字母+汉字。这里的汉字就是一级简码对应的汉字。由于要尽可能地使用常用汉字作为一级简码对应的汉字,所以部分汉字可能并不属于该区域,比如“不”,首笔画为横(一),应属于横区(1 号区),但其简码为 I,属于捺区(4 号区)。下面列表说明一级简码对应的汉字及其全码:
| 一级简码 | 汉字 | 全码 |
|---|---|---|
| Q | 我 | TRNT |
| W | 人 | WWWW |
| E | 有 | DEF |
| R | 的 | RQYY |
| T | 和 | TKG |
| Y | 主 | YGD |
| U | 产 | UTE |
| I | 不 | GII |
| O | 为 | YLYI |
| P | 这 | YPI |
| A | 工 | AAAA |
| S | 要 | SVF |
| D | 在 | DHFD |
| F | 地 | FBN |
| G | 一 | GGLL |
| H | 上 | HHGG |
| J | 是 | JGHU |
| K | 中 | KHK |
| L | 国 | LGYI |
| M | 同 | MGKD |
| X | 经 | XCAG |
| C | 以 | NYWY |
| V | 发 | NTCY |
| B | 了 | BNH |
| N | 民 | NAV |
这些一级简码务必熟练,从而提高输入效率。直接记忆可能比较困难,建议边练习边记忆。
建议记忆简码时加上空格,比如对于“我”字,记忆其简码时应记为 “Q + 空格”,一方面这样才能敲出该字,另一方面方便后续进阶“五码自动顶屏”。后续二级简码和三级简码也类似。
二级、三级简码
二级、三级简码和一级简码类似,是为了提高输入效率而出现的,分别对应按两个、三个按键就能输入一个汉字的编码,它们也都有对应的全码。与一级简码不同的是,部分一级简码并非是该字全码的首位(比如“不”字),而所有的二级或三级简码均为该字全码的前二或三位。记忆时同样建议加上空格
实际输入时,优先使用简码。
词组
除了单字最多敲击 4 个按键即可得出,词组也遵循此原则,即任意词组也最多敲击 4 个按键。事实上,词组刚好敲击 4 个按键。下面我们根据词组的字数来具体分析该敲击哪 4 个键。
双字词
取第一字的前两位编码和第二字的前两位编码,如“北”(UXN)+“京”(YIU)=“北京”(UXYI)。可简记为 2+2。
三字词
取第一字的第一位编码,第二位的第一位编码,第三字的前两位编码,如“毛”(TFNV)+“泽”(ICFH)+“东”(AII)=“毛泽东”(TIAI)。可简记为 1+1+2。
四字词
取每一个字的第一位编码,如“六”(UYGY)+“十”(FGH)+“四”(LHNG)+“卦”(FFHY)=“六十四卦”(UFLF)。可简记为 1+1+1+1。
多字词
取一、二、三、末字的第一位编码,如“中”(KHK)+“国”(LGYI)+“共”(AWU)+“产”(UTE)+“党”(IPKQ)=“中国共产党”(KLAI)。可简记为 1+1+1+1。
由于词组的输入效率是极高的,所以推荐实际输入时,优先使用词组,尤其是多字词。
特殊键
“Z”键
“Z”键也被称为“万能键”,有人将其用于代替不确定的字根,也有人将其用于实现拼音反查五笔编码,也有人将其用于特殊字符输入功能,还有人将其用作重复上一次输入的汉字。每个人喜欢的用法不尽相同,所以看个人的喜好。我是将其用于实现拼音反查五笔及特殊字符输入。
“L”键
“L”键的一个用途前面已经提到,即所有的单笔画字均使用“两个单笔画字母加两个L”,如撇(丿)的编码是 TTLL 等。
此外,“L”键还用于解决某些重码问题,比如对于词组“劳动”和“蔻”字,其编码均应为 APFC,但“劳动”显然更常用,为避免重码,就将不常用的“蔻”字的末笔编码改为了 L,即 APFL。又如“大”和“靥”也有类似的现象。
细节/注意事项
除了前述的一般规则外,五笔输入法中还有大量不符合一般规则的特例,这些特例有的也遵循一定规律,有的已经无法明确其缘由所在。这部分内容较多且较杂,目前我掌握得也不多,等后续充分掌握后再完善。当前可参见 【五笔输入法(三)】一文厘清五笔打字拆字疑难杂症 - 知乎
练习
要想学好五笔,除了有技巧地记忆大量信息外还需要大量的练习,边练边记方为上策。下面罗列一些常用的练习网站:
相关链接
主要参考链接:
其他相关链接:
- 5分钟学会五笔 (不用背口诀) - lcx1997 - 博客园
- 86版五笔输入法教学 2023.11.07 - 知乎
- 86版五笔教程 - 习惯沉淀 - 博客园
- 有关86版五笔学习笔记 - 知乎
- 五笔字型86版学习指南:字根分布、编码规则与拆字原则详解-CSDN博客
- 新世纪五笔字型资源库
附录
86 版五笔字根图
五笔偏旁部首拆分及编码速查
TODO:
- 需要进一步完善更多偏旁
- 需要添加拆分列和简码列
横区(G F D S A)
| 偏旁 | 五笔码 |
|---|---|
| 一 | GGLL |
| 廾 | AGTH |
| 匚 | AGN |
| 艹 | AGHH |
| 工 | AAAA |
竖区(H J K L M)
| 偏旁 | 五笔码 |
|---|---|
| 丨 | HHLL |
| 虍 | HAV |
| 卜 | HHY |
| 攴 | HCU |
| 刂 | JHH |
| 囗 | LNHG |
| 冂 | MHN |
| 殳 | MCU |
撇区(T R E W Q)
| 偏旁 | 五笔码 |
|---|---|
| 丿 | TTLL |
| 彳 | TTTH |
| 夂 | TTNY |
| 攵 | TTGY |
| 乇 | TAV |
| 豸 | EER |
| 彡 | ETTT |
| 勹 | QTN |
| 犭 | QTE |
| 饣 | QNB |
| 钅 | QTGN |
捺区(Y U I O P)
| 偏旁 | 五笔码 |
|---|---|
| 丶 | YYLL |
| 讠 | YYN |
| 亠 | YYG |
| 丬 | UYGH |
| 疒 | UYGG |
| 氵 | IYYG |
| 灬 | OYYY |
| 宀 | PYYN |
| 礻 | PYI |
| 衤 | PUI |
| 冖 | PYN |
| 廴 | PNY |
| 辶 | PYNY |
折区(N B V C X)
| 偏旁 | 五笔码 |
|---|---|
| 乙 | NNLL |
| 爿 | NHDE |
| 疋 | NHI |
| 忄 | NYHY |
| 屮 | BHK |
| 阝 | BNH |
| 凵 | BNH |
| 卩 | BNH |
| 彐 | VNGG |
| 厶 | CNY |
| 幺 | XNNY |
| 糸 | XIU |
| 弓 | XNG |